
A valuable component of corporate governance is the risk register. Although it is not mandatory, using a risk register to build a sound risk governance process for an organization is strongly recommended. A risk register is a collection of identified risk scenarios that are accounted for and incorporated into the enterprisewide risk profile. It is the compass of the risk response plan because it represents the main reference for all risk-related information, supporting risk-related decisions and prioritizing risk response activities.
As defined in the CRISC® Review Manual 6th Edition, “[O]rganizations maintain risk registers in order to consolidate all information about risk into one central repository.”1 In other words, “to obtain the status of the risk management process from a single source.”2 The strength of these sentences lies in the words “one” and “single,” which mean global and centralized. The link between enterprise objectives and the operations to support them is made possible by the presence of a single archive for sharing all control information.
This central archive is an extremely valuable and critical resource, as it crosses all enterprise processes. All the information useful for assessing and treating enterprise risk is consolidated in this archive and, consequently, maximum care must be taken in its maintenance. For example, there is a cyclical need for a timely and careful attribution of accountability; the continuous accuracy in updating the analyzed context; the optimization of performance, risk and maturity indicators; the necessary sharing of contents to increase awareness of risk issues; or looking for simplification for greater clarity in communication. In other words, organizations are always trying to improve to create new added value.
A new front for improvement can be found by examining the completeness of the information included in the risk register, which acts as a container for all risk scenarios. In the case of risk scenarios for IT specifically, the classification of the data as an internal risk factor must be permanently included. It is not an additional piece to be managed, but a precise set of objectives to be respected, which needs to receive adequate organizational attention.
Often, the classification of data is exposed at the policy level without a clear operational attribution, while other times it is exposed at the operational level without a clear reference to business objectives. To provide evidence of both alignment with objectives and linkage with controls, the right placement is in the risk register. This solution can be practically implemented without burdening the risk scenario while also helping internal control find the right solution for data classification.
Risk Register
The risk register is comparable to a relational table made up of key fields and attribute fields. The key fields identify a risk scenario for an asset (risk identification domain), while the remaining fields are those that qualify it (risk assessment domain) and establish its treatment (risk response domain). Each single registration is identified by a unique key (figure 1) defined by three main elements related to each other: the risk event (i.e., the conditions for the occurrence of the threat), the resource (i.e., the tangible or intangible asset, or its part, to be protected from the risk) and the threat (i.e., the potential cause of the risk, internal or external).
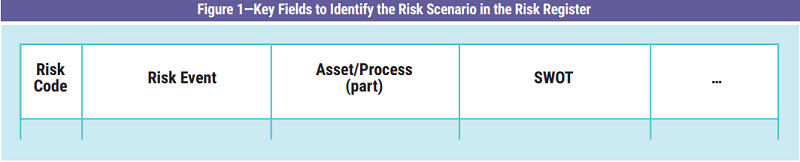
A threat (or a set of threats) is identified according to the asset to be protected. More precisely, it is a combination of risk factors including strengths, weaknesses, opportunities and threats (SWOT). A threat does not necessarily have to be negative, it can also be viewed as an opportunity. A risk event is a function of the risk factors, external or internal, that may occur. It is qualified during the assessment, control and audit phases or as management input. A threat is against an asset that is important to business objectives.
These elements are represented by three lists, whose members can increase or decrease depending on the context analyses that are periodically carried out. By combining an element from each list and adding objective parameters, descriptions and evaluations of indicators, a complete risk scenario is created. The enhancement of the scenario with the current state and with the controls to achieve the desired state is the task of the organization’s risk management process.
THE RISK REGISTER MANAGEMENT PROCESS IS SIMILAR TO THAT OF DATA CLASSIFICATION.The importance of the risk register management process is made clear by the steps in its operating cycle. It starts from the business objectives and then it identifies the possible causes of uncertainty, includes the response measures, collects the outcome of the controls and communicates everything to top management for the resulting decisions (based on risk). Then, the risk management cycle restarts with the new top management guidelines. Top management should also be included to define the risk acceptance threshold so that it is aligned with corporate objectives.
The risk register management process is similar to that of data classification. The data classification defines the threshold beyond which inevitable damage to the organization will emerge and should also be approved by top management. From this consideration, it is intuitive to place the data classification in the risk register since the classification defines a protection objective, with the need for approval by top management, to commit resources to protect the asset itself and to optimize the value of the asset for the organization. This is similar to some situations encountered in the risk management cycle. The classification of data finds its natural home in this registry.
As important as it may be, an operational process cannot be used to determine the data protection objective. For example, the information and communications technology (ICT) process manages the processing and storage of billing data but is not the owner of the data. The accounting process is presumably the owner of the data but does not decide on the duration of storage; regulations decide this. In any case, even assuming that the accounting suggests the most correct action, it will still be those who respond to the corporate objectives who decide whether or not to approve any issue with an impact on the objectives themselves.
Data Classification
After top management has defined the objective of protecting an enterprise asset, the operational process ensures that the objective is safeguarded for the entire duration of the asset’s life. This security activity should be performed as effectively and efficiently as possible, hence the need to access an exhaustive context reference framework (objective value) and data classification values to be compared with the evaluation of the performance achieved by operational control (measured value). Failure to comply with the data classification impacts the assessment and the probability of occurrence of the risk event.
Following the implementation of the controls, the audit process must ensure that the activities are aligned with the objectives. For conformity assessment, it is essential to always have easy and full access to the implementation requirements, including the objectives. The advantage of having them all in a single document (i.e., the risk register) is twofold. The document is drawn up according to rules that impose narrative simplicity to facilitate communication and, cyclically, it is subject to management review, which guarantees alignment with the objectives of the organization.
Including the classification of the data in the risk register improves various phases of the risk management process. For example, the classification of the data is a parameter that can be used as an internal risk factor, contributes to improving the assessment of impact and probability, guides the design of controls, provides a reference element for audits, and is usable in the management review.
Given its usefulness, it is important to understand how to manage the classification of data in the organization’s risk register. To make the information easily usable in this context, only a few elements should be managed and they must be sought in such a way as to be clearly understandable to both managerial and operational positions.
The risk register is a transversal document for the entire organization. Senior management initializes the alignment parameters to the business objectives and the operating staff updates the controls accordingly. Therefore, it must have a simple structure and any excess information should be delegated to another document. The suitable tool to cover the details necessary for a correct evaluation of impact and probability, in the case of business continuity management, is the business impact analysis (BIA).3 This document is a cornerstone of the organization and it is likely that many organizations do not need anything else.
THE RISK SCENARIOS IDENTIFIED FOR BUSINESS CONTINUITY SHOULD, IDEALLY, BE A SUBSET OF THE CENTRAL RISK REGISTER.The BIA is created for business continuity management. The risk scenarios identified for business continuity should, ideally, be a subset of the central risk register. The BIA must be aligned with the business objectives and this can be achieved by linking it to the common risk scenario that has already been defined in the register. Even the records in the register relating to the pure achievement of specific performance (e.g., financial area) are indirectly linked to business continuity. In the analysis of the impact of business continuity, the consequences attributable to these records will also be considered, avoiding the unnecessary use of operational details.
The risk scenario is represented by a descriptive record of an asset, a process or, more likely, a category where all the elements have similar security requirements. In the case of an asset with a specific need, a new record can be generated by duplicating an existing one.
For example, the generic firewall category has its own scenario qualitatively defined as a standard reference of protection measures common to all firewalls, that is, a security baseline for all the elements represented in that category. If one of these is installed in a zone that requires a security measure not covered by the security baseline, then a new instance is created for the additional requirements. If the risk scenario changes, the standard risk register record is duplicated and the new record is changed with the additional requirements. If only the operational activity necessary to satisfy a more stringent assessment changes, the corresponding record in the BIA is duplicated and the data relating to the management of this exception are changed.
Information Security Triad
The level of security required for information establishes whether it needs to be protected, and it is customary to use the information security triad, which includes confidentiality, integrity and availability (CIA).4
The first step is deciding where to place the CIA triad in the register. The risk scenario record is typically read from left to right; therefore, the CIA triad can be placed before the impact and probability fields used for risk analysis (figure 2). This position ensures that the established security constraints are known before proceeding with the estimation of the impact and probability. This additional information improves the perception of the consequences in the event of failure to achieve the protection objective.
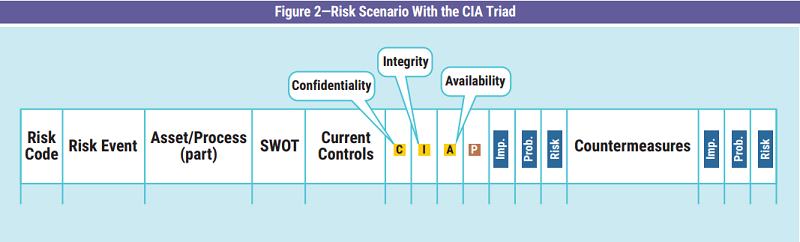
To effectively manage the CIA triad, it is important to define how to handle its three parameters and which levels to use. For easy use, both to define the goal and to understand it, it is necessary to operate with a low number of levels for each parameter, selecting only those with the best ability to clearly summarize the concepts. Although not all organizations use the same set, it is possible to use a common starting point.
Confidentiality
The first parameter is confidentiality. It states the
set of subjects authorized to access the
information and the methods allowed for its
circulation. The metric chosen for the confidentiality
objective must be able to provide a confidentiality
value of the data and define the limit imposed on its
communication to other subjects. It can be
summarized with four qualitative levels (figure 3).
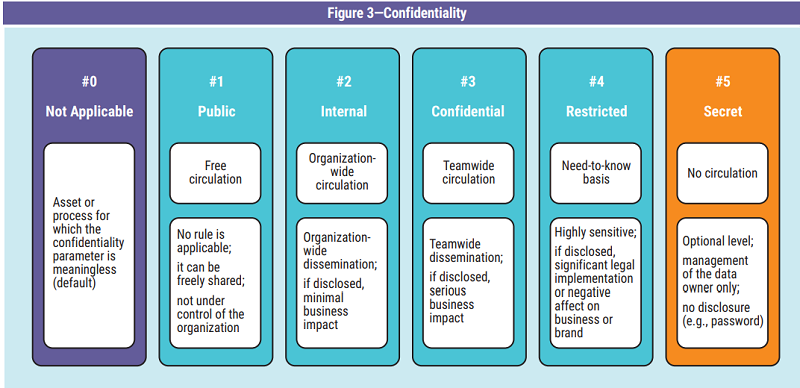
The public level includes data without barriers and that are unable to harm the organization. Typically, these are the data found on Internet sites without any need for authentication access. When it is established that the level is public, it is unnecessary to apply rules to this category because it has been placed outside the control of the organization. Consequently, the dissemination of this information does not require any authorization and cannot imply any consequences.
Internal-level data can be freely circulated, but only within the organization’s boundaries or other formally authorized subjects. This type of data are typically found on organization bulletin boards that anyone in the organization can freely consult, but it is prohibited to communicate them outside the organization perimeter, unless otherwise authorized. In the event of unauthorized external exposure, the impact on business objectives is reasonably limited.
The confidential level includes data that require an identification and filtering system for the subjects who access the information. These are the data that are found in meetings restricted to a specific list of guests. The owner of the data must grant authorized credentials to access the data. Exposure of the data externally to all the legally authorized parties could negatively affect the objectives or organization’s image.
The restricted level includes information for a small circle of subjects with traced circulation between them. Typically, this includes information found during research and development that represents a technological competitive advantage. The requirements are not only strong authentication for access, but also the need for a secure communication channel. If this information is exposed externally to unauthorized parties, it could compromise the achievement of objectives or even cause serious legal problems.
If necessary, an extreme level can be added for information with no circulation except by its owner. Examples of this type of information include authentication credentials, a new nonpatented chemical formula or cryptographic keys used in communication systems. If the information was improperly exposed, it could create a dangerous breach in the security system, which could compromise the organization.
Integrity
The second parameter is integrity. It expresses the
level of protection of the information against
unauthorized modification. The chosen metric must
be able to provide an assessment of the possibility of data alteration. It can be summarized with three
qualitative levels (figure 4) associated with the
different types of change control.
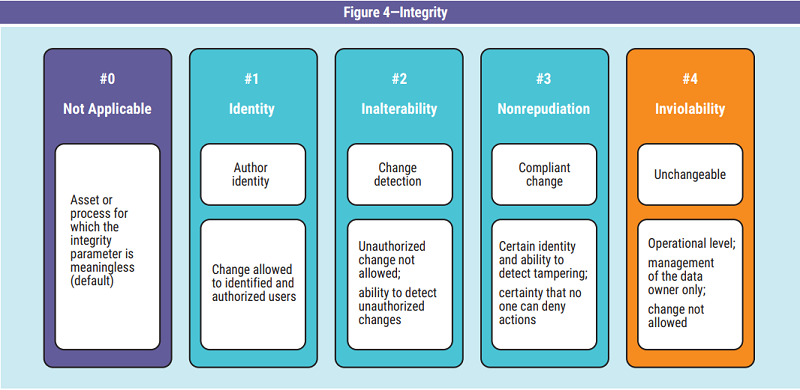
The first level is the guarantee of recognition of the author’s identity before the modification. An access control mechanism is required, and it can be implemented by verifying the authentication credentials of the person who is accessing the data. Only authorized users are allowed to change the classified data. The mechanism chosen for identification should be described in the IT security guidelines. From an organizational point of view, at least two rules are expected: User access permissions are subject to periodic review, and appropriate training is provided to educate users on the use and storage of authentication credentials.
The second level is the guaranteed ability to recognize unauthorized alterations of the data. In the modification operation, the automatic registration of additional information is required to subsequently identify any illegal changes to the original authorized data (e.g., by means of a hash or checksum). Alternatively, stakeholders must ensure that no changes are made by recording a copy in an environment that cannot be breached by unwanted subjects. The choice of the protection mechanism should be defined in the BIA to ensure a solution that maximizes value with respect to the objectives.
The third level is the guarantee that the author of the data cannot deny the authorship and validity of the modification made. A process is required that guarantees both aspects (i.e., that only authorized and well-identified subjects can access in modification and that there is no possibility of altering the data without leaving a trace of this). The solution is not easy, as a simple, cheap and realistically reliable reference solution has not been identified for trusted third parties (TTPs). It may be necessary to rely on strong authentication mechanisms and public key cryptography systems or the use of blockchain technology.
The last level is for extreme cases. The data, after being generated, can no longer undergo any changes. Absolute guarantee that the original value cannot be changed after its generation is required. For example, this is the case with ROM memory or nonrewritable optical media.
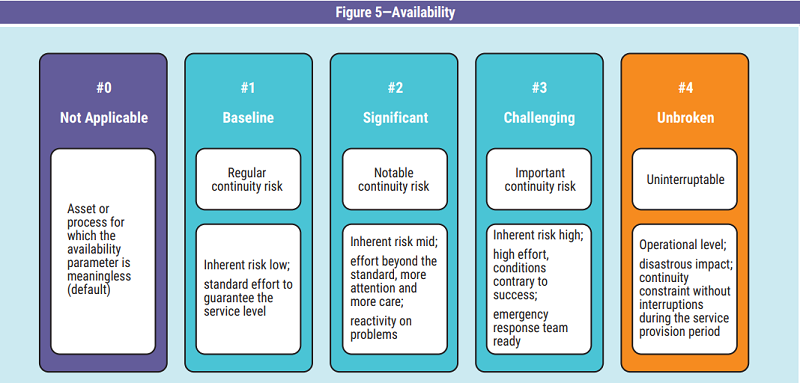
Availability
The third parameter of the CIA triad is availability. It
guarantees access to information by legitimate
users when they request it. The metric chosen must
be able to provide a resource availability value in
compliance with predefined times or any admissible
data losses. It can be summarized with three
qualitative levels (figure 5) linked to the ability to
react and the tolerability of the loss.
This parameter is strongly linked to operational continuity and can manage service-type resources or systems. Compared to the other data classification parameters, the definition of the availability objective is more complicated because it often requires accurate data, and the qualitative declarations are not always sufficiently exhaustive. Furthermore, in the risk register, it is always preferable, whenever possible, to use categories of assets rather than specific assets because it increases the readability by top management.
To take advantage of these benefits, it is necessary to resort to another document for the details such as the BIA. The BIA was created as an in-depth document to analyze the impacts on business objectives and preserve all the characteristic values of each relevant asset. However, it is important to always ensure the link between the detailed record of the impact of the BIA and its reference in the risk register to ensure consistency and avoid the unnecessary redundancy of information.
Baseline Level
This level corresponds to the measures normally
ensured when continuity constraints and
operational risk levels are deemed acceptable. It
refers to the general protection measures described
in the security policies and integrated with
procedures for operational measures. The baseline
represents the set of normal measures
implemented to ensure the minimum levels of
continuity expected in conditions without
particularly serious repercussions in the event of
incidents.
Significant Level
This level corresponds to additional measures
applied with respect to those defined in the
baseline: When continuity constraints and
operational risk are significant, greater attention is
required than conventional measures. In this
situation, it is likely that continuity indicators5
are
established in the BIA such as the maximum
tolerable downtime (MTD) and the recovery point
objective (RPO). These values require additional
actions compared to the standard, but they are not
particularly demanding or burdensome to
implement and the consequences of any
shortcomings could be serious but not critical.
Challenging Level
This level corresponds to the heaviest measures to
be applied when continuity constraints are vital and
the risk conditions to ensure that operations are
highly adverse. The high level of criticality in
respecting the high availability parameters for
business continuity requires considerable effort
and, if not addressed, there will be extremely severe
consequences. This is a situation where a lack of
control or an incorrect evaluation of a key
performance indicator (KPI) in critical processes
must be classified as an incident and not as a trivial
decrease in performance.
Unbroken Level
There may be a need for an additional option as an
upper limit in the case of a system with a continuity
constraint without any possibility of interruption or
loss of data, and, if this occurs, it will lead to the
failure of the entire organization. Examples include
an air navigation system, a radioactive leak alarm
system and the oven temperature sensor when
cooking a cake. This situation will require careful
risk analysis, and among the consequent
countermeasures, there will be redundancy on the
critical components to allow continuity in adverse
situations and ensure the absence of data loss.
Significant costs are expected, but they are justified
by the risk analysis that provides the elements to
decide between the admissibility of the risk and the
mitigation of the risk.
Protection of Personal Data
The CIA triad may seem sufficient to establish the correct classification of the data; however, the increase in importance of protection of personal data requires careful consideration. It should be noted that, in the countries where the protection of personal data is regulated, this is a mandatory legal requirement derived from governing bodies, not just a requirement derived from an internal policy. This means it cannot be judged by the organization, and the general rules are required by law. Since the protection of personal data is an external risk factor, it is mandatory to manage it in the risk register. Furthermore, since it is mandatory to treat it, the only possible response is to mitigate the risk.
This can be managed with an additional parameter to the CIA triad that is dedicated exclusively to privacy (figure 6). The goal of protecting personal data is established by choosing between two possible values related to the different legal treatments required (figure 7).
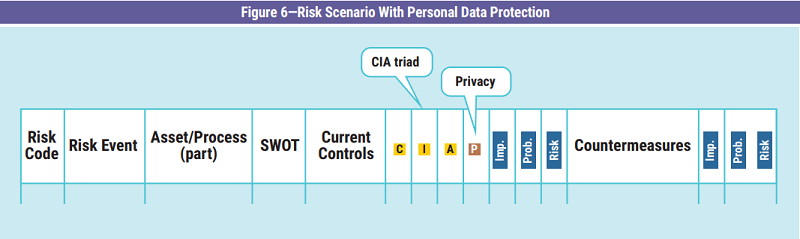
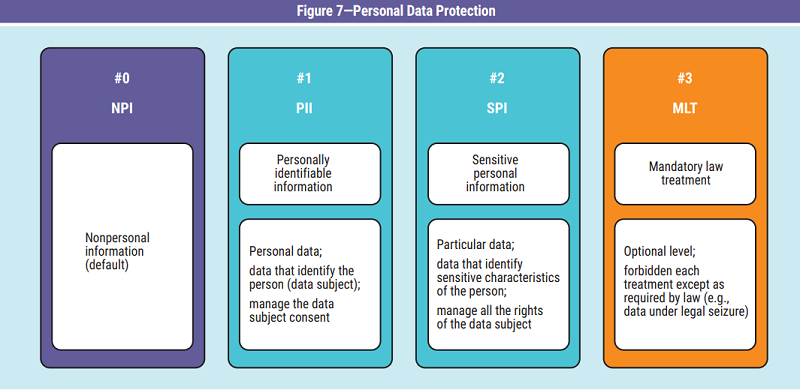
Personally Identifiable Information
Personally identifiable information (PII)6
allows the
identification of a person but, if not associated with
further information, does not reveal other personal
characteristics including physical particularities,
lifestyle, preferences, beliefs, geolocation over time,
network activities, profiling or health status. It is the
identification of a person in a specific context
without being able to add further knowledge on the
characteristics of the person. The confidentiality
classification is internal or confidential.
Sensitive Personal Information
Sensitive personal information (SPI)7
consists of the
identification of a person and additional attributes
that in some way can have a significant impact on the
person concerned. These particular data, which
characterize the person, are subject to greater
protection by the law because they can potentially
cause damage to the data subject, depending on the context in which they are exposed. Particular
attention should be paid when different data,
individually with no apparent value, are combined to
compose new information with personal interest (e.g.,
as a response to a query). The temporary correlation
of anonymous data can create sensitive information
and the related process must be classified. The
confidentiality classification is restricted.
Mandatory Law Treatment
Personal data can also be protected by the law. An
example is a law request for specific processing
following a breach, such as in the case of a data
breach. Consequences include the seizure of a
system or having to keep a forensic copy or other
constraints that also impact the personal data
included. It could be a temporary state, but it must
be managed with different rules than those
expected for PII or SPI states and, therefore, may
require a different classification.
The determination of the exact classification is identified following a data protection impact assessment (DPIA),8 which is strongly recommended even when there is no legal obligation (required in the case of high risk). Operationally, a DPIA could easily be derived as a subset of the BIA.9 With respect to nonpersonal data, the impact on information systems must also be considered as a result of the exercise of the legal rights of the individual (e.g., the right to correction or cancellation, right to access, right to portability), which involve specific actions and additional charges to be included in the risk analysis.
FOR AN ORGANIZATION, DATA CLASSIFICATION IS THE COMPASS THAT CORRECTLY ORIENTS ITS INFORMATION SECURITY SYSTEM.Conclusion
Considering the classification of data as a mandatory step to compile tables is a prospect that is unlikely to grasp the usefulness and necessity of this process. For an organization, data classification is the compass that correctly orients its information security system. It is a process that must be built under the direction of top management (guaranteeing alignment with business objectives); therefore, the components of this process must be manageable and intuitive. The best tool to do this is the enterprise risk register because it likely already exists and uses the same interconnections required by data classification.
Creating a new process makes little sense because it does not simplify internal processes. According to the Agile methodology, an organization should start with what they have and work to improve cyclically over time. It is better to reuse what already exists and add value with proper attention to what needs it without adding too much complexity. Anything that exists in the risk register that cannot be established at an aggregate level or by category can be moved to a different document of greater detail (e.g., the BIA).
To improve the quality of the overall business risk scenario and provide a more accurate evaluation of impact and probability, the data classification parameters should also include privacy. Further, the risk register shows evidence of the involvement of top management in defining the guiding criteria for business continuity planning. This simplifies the auditing of the assignment of responsibilities during management review. Furthermore, having multiple types of information interconnected with each other in the same document allows for a more agile (and timely) update.
Endnotes
1 ISACA®, CRISC® Review Manual 6th Edition, USA, 2015, https://www.isaca.org/resources
2 Ibid.
3 International Organization for Standardization (ISO), Technical Specification (TS) ISO/TS 22317:2015 Societal security—Business continuity management systems—Guidelines for business impact analysis (BIA), Switzerland, 2015, https://www.iso.org/standard/50054.html
4 International Organization for Standardization (ISO)/International Electrotechnical Commission (IEC), ISO/IEC 27000:2018 Information technology—Security techniques—Information security management systems—Overview and vocabulary, Switzerland, 2018, https://www.iso.org/standard/73906.html
5 Swanson, M.; P. Bowen; A. W. Phillips; D. Gallup; D. Lynes; Contingency Planning Guide for Federal Information Systems, Special Publication (SP) 800-34 Rev.1, National Institute of Standards and Technology (NIST), USA, May 2010, https://csrc.nist.gov/publications/detail/sp/800-34/rev-1/final
6 McCallister, E.; T. Grance; K. Scarfone; Guide to Protecting the Confidentiality of Personally Identifiable Information (PII), Special Publication (SP) 800-122, National Institute of Standards and Technology (NIST), USA, April 2010, https://csrc.nist.gov/publications/detail/sp/800-122/final
7 Northeastern University Office of Information Security, Boston, Massachusetts, USA, “What Is Sensitive Personal Identifying Information (PII)?” SecureNU
8 European Commission Article 29 Working Party, “Guidelines on Data Protection Impact Assessment (DPIA) (wp248rev.01),” Belgium, 2017, http://ec.europa.eu/newsroom/document.cfm?doc_id=44137
9 Sbriz, L.; “Enterprise Risk Monitoring Methodology, Part 1,” ISACA® Journal, vol. 2, 2019, https://www.isaca.org/archives
Luigi Sbriz, CISM, CRISC, CDPSE, ISO/IEC 27001 LA, ITIL v4, UNI 11697:2017 DPO
Has been the risk monitoring manager at a multinational automotive company for more than five years. Previously he was responsible for information and communication operations and resources in the APAC Region (China, Japan and Malaysia) and, before that, was the worldwide information security officer for more than seven years. For internal risk monitoring, he developed an original methodology merging an operational risk analysis with a consequent risk assessment driven by the maturity level of the controls. He also designed a cybermonitoring tool and an integrated system between risk monitoring, maturity model and internal audit. Sbriz was a consultant for business intelligence systems for several years. He can be contacted at https://it.linkedin.com/in/luigisbriz or http://sbriz.tel