
There is no question that data risk equates to enterprise risk. Evidence of this is articulated in the origins of the Basel Committee on Banking Supervision’s BCBS239 regulation that was developed as a risk management response to shortcomings identified in international bank management during the global financial crisis of 2007-2008.1 BCBS239 required stringent bank data management practices to enable higher quality bank risk data aggregation and risk reporting as a risk control against adverse market effects on bank continuity.2
Knowing that data risk is enterprise risk nurtures the organizational mindset needed to develop and implement strong enterprise data management practices. While not all sectors are subject to regulations for managing data risk, figure 1 shows examples of how various industries are exposed to data risk. Every industry that collects, stores, and/or uses data is exposed to data risk, and its potential impact can be reduced by implementing appropriate data risk controls.

A strong, risk-based business case helps create senior executive visibility into data-driven enterprise risk. The benefits of this visibility materialize in the much-needed executive support and resourcing critical to the success of enterprise data initiatives, and consequently, to the reduction of the enterprise’s risk profile. A well-rounded business case with the necessary executive champion helps secure some sustainability for an enterprise’s data risk initiatives.
And just who is the subject of the recommended executive visibility? Good candidates would be the chief risk officer (CRO), the chief operations officer (COO), or even the head of internal audit. BCBS239 resulted in organizational structures such as the office of the chief data officer being established to provide some gravitas for its eponymous lead role in the previous decade.3 As in all risk management contexts, one needs to be careful to mitigate the potential conflicts of interest implied in some of the reporting lines of data risk management officials..
Another supporting argument for data risk as enterprise risk takes the form of today’s data resilience endeavors. Data resilience can be defined as the ability of an enterprise to manage data in a way that supports its ability to rebound from an adverse event.4 In turn, an adverse event can be considered any uncertain event that negatively impacts the ability of an enterprise to achieve its planned objectives. In other words, data resilience is about managing data risk in a manner that ensures that an adverse event does not constrain the enterprise from achieving its objectives. Indeed, the discipline of data risk management is key to organizational resilience.5
Enterprise Risk: The Data Connection
One way of categorizing enterprise risk is by internal or external risk. Internal risk factors are fully within the enterprise’s control6 because they originate as a result of what an enterprise does (or does not do). In contrast, external risk factors are not fully within an enterprise’s control.7 Current external enterprise risk factors include geopolitical uncertainty, elevated inflation, and climate change.8
While it is not in an enterprise’s ambit to control external risk factors directly, it still needs to prepare an organizational response to them in the interests of organizational sustainability.
Controllable, internal risk types typically include audit risk, control risk, operational risk, security risk, schedule risk, strategy risk, project risk, compliance risk, IT risk, and quality risk.9 It is when one considers the impact of data on these risk factors that the connection between data risk and enterprise risk becomes clear. As an example, consider operational risk, audit risk, IT risk, privacy risk, and security risk, the types of risk typically of interest to digital trust professionals (figure 2).
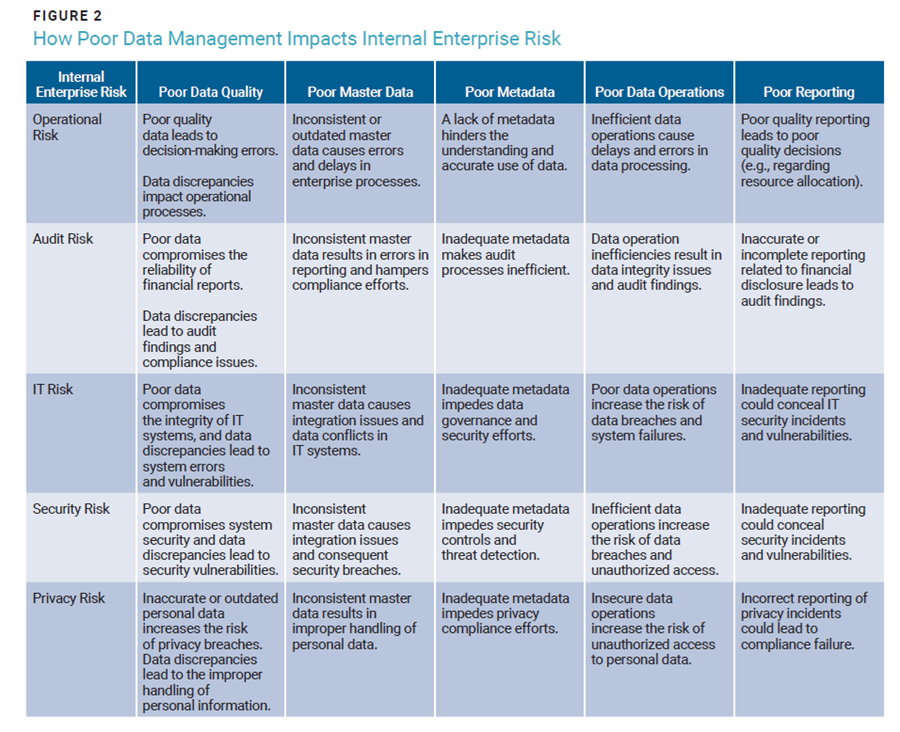
While each data management aspect shown in figure 2—and others—should be analyzed with respect to their contributions to enterprise risk, in the interest of space, only data quality will be explored in this article. Data quality generally has the most visibility—in terms of both impact and frequency—not only to data management specialists and regulators, but also to the general public.
Given the importance of a semantic layer (as provided by metadata) for an enterprise’s most important data elements, an overview of metadata will be presented to offer an idea of the risk to which poor or nonexistent metadata contribute.
Data Quality Remediation as an Enterprise Risk Control
Data quality is not a new development. While Basel’s BCBS239 was only written in 2013, the origin of data quality can be traced back to the 1920s and 1930s.10 Yet the poor state of enterprise data quality today is well documented. Many enterprises—even large ones such as Unity Technologies, Equifax, Uber, Samsung, and Public Health England—still struggle with data quality.11 Today, poor-quality data presents a significant risk to data-driven decision making. But how does one determine the most important elements of quality data, and thus which data elements are important from a risk identification perspective? Enter that underused construct in data architecture: The conceptual data architecture. It is a higher-level architecture than logical and physical data architectures, providing the clarity needed for a non-technical understanding of the essential entities (e.g. citizens, customers, patients, students, products, and services) and their interactions (e.g. voting, sales, doctor’s visits, exams) in an enterprise. This clarity helps diverse stakeholders identify key data elements, their flows, and their uses, enabling the risk factors associated with those flows and uses to be easily identified.
Data quality largely concerns the accuracy and reliability of several types of data records:
- Entity (master data) and category/group/class data (reference data)—Inconsistent master data and reference data quality across enterprise systems is a primary driver of poor data interoperability.12 Building on the healthcare example in figure 1, poor data interoperability can lead to poor patient outcomes, or even death.13
- Interaction data (transactions)—Financially and operationally, inaccurate transactional data makes it difficult to determine the true financial and operational state of an enterprise at any point in time, especially for those critical working capital items such as inventory (stock), cash balances, accounts receivable, accounts payable, and short-term debt instrument commitments.
- Unstructured data and information (e.g. sound recordings, video recordings, photographs, scanned documents including handwritten artifacts)—The challenge with this information is perhaps less about its quality, and more about its usability and its ability to be integrated with other types of data for analysis. In other words, the quality aspect is largely about data interoperability and integration.
The reason for the continued struggle for data quality is not hard to grasp when one understands the complexities inherent in addressing poor-quality data at the enterprise level. One of the major questions facing data restitution (data cleansing) concerns is, where in the data value chain should data quality be addressed? Should it be addressed at the point of capture, or even earlier, at the point of design? Or can it adequately be addressed further downstream, such as in the data warehouse, data lakehouse, or data vault, or even further downstream, such as at the point where data is used in a report or piece of analysis for decision making?
Ideally, data quality should be addressed at the design phase, or at the latest, at the point of capture. But for most enterprises, it is too late for that, especially in a high legacy environment. The reason upstream is the ideal point for data remediation is that data captured correctly or corrected at source means that all occurrences of those data elements transported downstream are inherently correct as well, without requiring any further effort. The further downstream data is corrected, the higher the enterprise risk of having different versions of the same data in existence. A challenge for the enterprise is that front-end enterprise processes may not allow sufficient time for quality data capture by frontline staff.
There can, however, be a compelling reason for not performing data remediation at source: the high volume of records that may need correcting. For front-end staff to address each record through the user interface takes valuable time away from that staff member being able to perform their customer-facing job, especially when hundreds or thousands more await remediation. Today, risk-mature enterprises create job descriptions for front-end roles that include responsibilities for data quality at the point of capture as part of a data risk control, before the volume of data needing remediation escalates.
To ultimately address the remediation volume issue at the source, some propose bulk data updates in the production system through the back end. The enterprise risk of this is significant because there is typically no visibility into the database schema (data model) or its processes for commercially procured systems. This means there is no visibility of all the tables impacted (e.g., by event-driven database triggers perhaps acting on invisible tables). In other words, performing bulk backend updates introduces the risk of the referential integrity of the database being negatively impacted, which can bring the entire enterprise to its knees.
This reasoning explains why some enterprises opt to perform their data quality initiatives downstream in the data warehouse or data lakehouse (see [a] and [b] in figure 3), or even further downstream (see [c] and [d] in figure 3), or perhaps all the way downstream for “just in time” remediation at the point of data use (e.g., for a report or a data product in the data mesh paradigm).
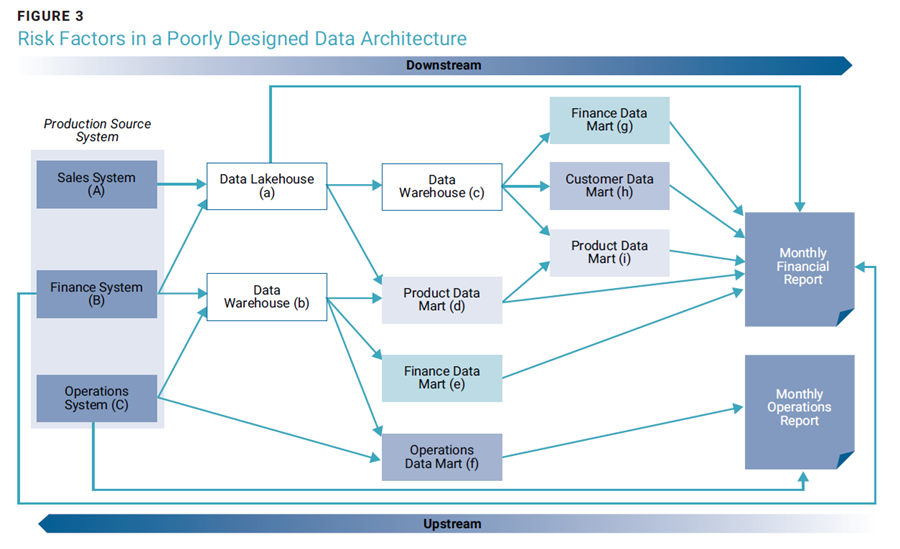
However, there is significant risk in performing data quality remediation so far downstream. For example, if the need were to remediate some of an enterprise’s financial data, instead of performing data remediation once at (b), the enterprise now needs to perform it at least twice for the two extra versions of the truth for a dataset at (e) and (g). Similarly, performing data remediation only at (g) would mean three versions of the truth: the production version, the corrected downstream version (g), and an uncorrected downstream version (a) which may or may not be identical to the production version. This lack of a single version of the truth ultimately leads to inconsistent internal reporting, risky decision making, and ultimately a worsened enterprise risk profile.
Good data architecture is a critical success factor for good digital transformation.14 The data platform materializing out of the data architecture represented by figure 3 would be fraught with operational risk, some of it driven by duplicated data transportation mechanisms for various critical data elements (e.g., by Extract-Transform-Load [ETL], Extract-Load- Transform [ELT], or even more complex transportation mechanisms). A good data architecture can help identify enterprise risk in advance, allowing corrections to be made before implementation.
There is much more to the problem of data quality though (figure 4). A failure in one part of the data quality ecosystem can amplify data-driven enterprise risk. In other words, a failure of a process, activity, or function can have negative implications for the performance of dependent processes,15 and thus for as many downstream processes that exist in the process chain.
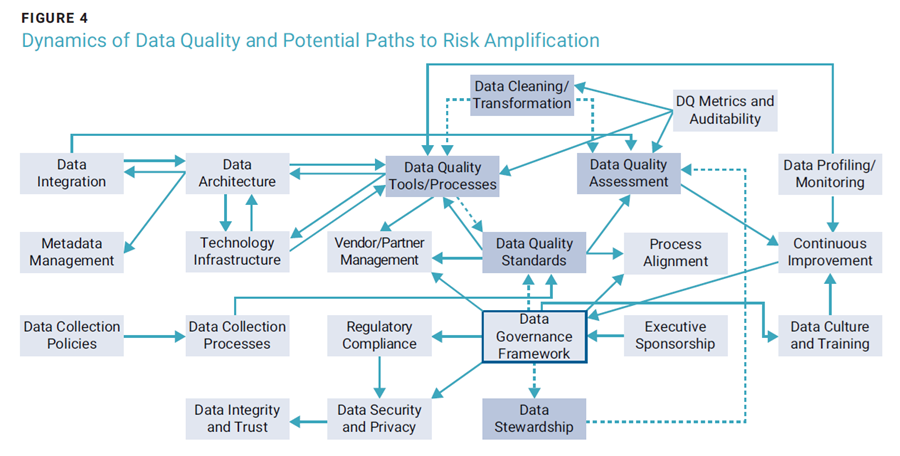
For example, consider the data cleansing activity in figure 4 (the topmost activity in the image). As depicted, data cleansing depends on sound data quality processes being defined, some of which might be automated in a data quality tool. In turn, the quality of those processes depends on defined data quality standards, which depends on the design explicit in the data governance framework. The data governance framework also defines the data stewardship model, which in turn is a driver of the data quality assessments, which are themselves driven by the aforementioned data quality processes.
In just this tiny part of the data quality ecosystem, any failure in any of these activities, for example, poor data steward roles and responsibilities defined in the data governance framework, negatively impacts the ability to perform the data quality assessments as expected, which will have a negative impact on data cleansing activities. The negative impact could be so large as to ultimately deem the enterprise’s data quality efforts a failure.
Data quality is a critical part of ensuring that enterprise data is fit-for-purpose for decision making. There are numerous areas where the risk of inaccurate data impacts enterprise risk, and the effect of risk in various parts of the data quality ecosystem could render enterprise data quality efforts to be ineffective.
Metadata Management as an Enterprise Risk Control
Just as metadata is a critical factor in security initiatives—i.e., the classification of data as public, internal, confidential, and restricted—so too is it for privacy. In privacy terms, the supporting metadata could be personally identifiable information (PII), sensitive personal information (SPI), material nonpublic information (MNPI), protected health information (PHI), and others.16 While no privacy data would fall into the “public” security category, it is distributed across the other three security categories. Getting this metadata wrong, or not having it at all, introduces the types of enterprise risk highlighted in figure 2.
Data classification is important to risk management for several reasons:
- It ensures that the location of sensitive data is known, which is very important in a data breach and for determining the type of response to the breach.
- It assists in ensuring compliance with data regulations governing certain types of data.
- It allows for the implementation of precise data security tools based on the classification of data.
In general, metadata is key to a well-functioning data quality ecosystem (figure 4). Metadata, such as data lineage (or data provenance), for the various data elements making up the reports in figure 3 is essential to determining whether a report (or data product) presents an accurate reflection of reality. Data lineage is a form of metadata at the critical data element level that shows where a data element comes from, and how it has been transformed over its path from its source to its point of usage.
For a report such as the “Monthly Operations Report” in figure 3, the data lineage metadata would detail the origins of each of the data elements used in the report, as well as how the data was transformed along the path from (c) to (f) to the report, and from (c) straight to the report. This enables the user of the report to determine the extent to which all of the data elements making up the report are an accurate reflection of the reality presented in the production systems. The greater the variance, the less trustworthy the report. This particular type of metadata is such an important component of enterprise (bank) risk management that it makes up part of bank reporting to regulators, especially for bank risk reporting.
For many enterprises, an important form of metadata is the data dictionary. A data dictionary explains what each critical data element means, how it should be used, and any other information about those critical data elements that might be important to know. It can also be an encompassing term for some other forms of metadata. As a risk control, a well-governed data dictionary provides accurate definitions of critical data elements for reporting and analysis rather than depending on anecdotes (that are lost when the relevant person leaves an organization) or a hopefully accurate interpretation of an otherwise cryptic column name in a relational database.
Creating an enterprise data dictionary is no mean feat; a good dictionary depends on a regularly reviewed vision, significant collaboration, and clear and concise definitions. There are also cases where no single definition exists for some data elements, resulting in the occurrence of approved synonyms in the data dictionary. Data lineage information is a critical part of the data dictionary, helping users understand where the enterprise’s critical data elements originate, and how they are used and transformed across the enterprise. Data classifications, such as the aforementioned security and privacy classifications, also constitute part of a good data dictionary.
Data Resilience Practices as Enterprise Risk Controls
At a greater level of abstraction, data resilience—the combination of governance, operational and technical considerations involved in mitigating organizational continuity risk due to adverse data-based events—concerns the active management of, for example, the usability, security, robustness, reliability, availability, capacity, interoperability, and performance of an organization’s entire data operating model.17
Figure 5 shows examples of enterprise data management activities that can help control some of the data-related risk enterprises face as a means to help protect them or to help them rebound from adverse data events.
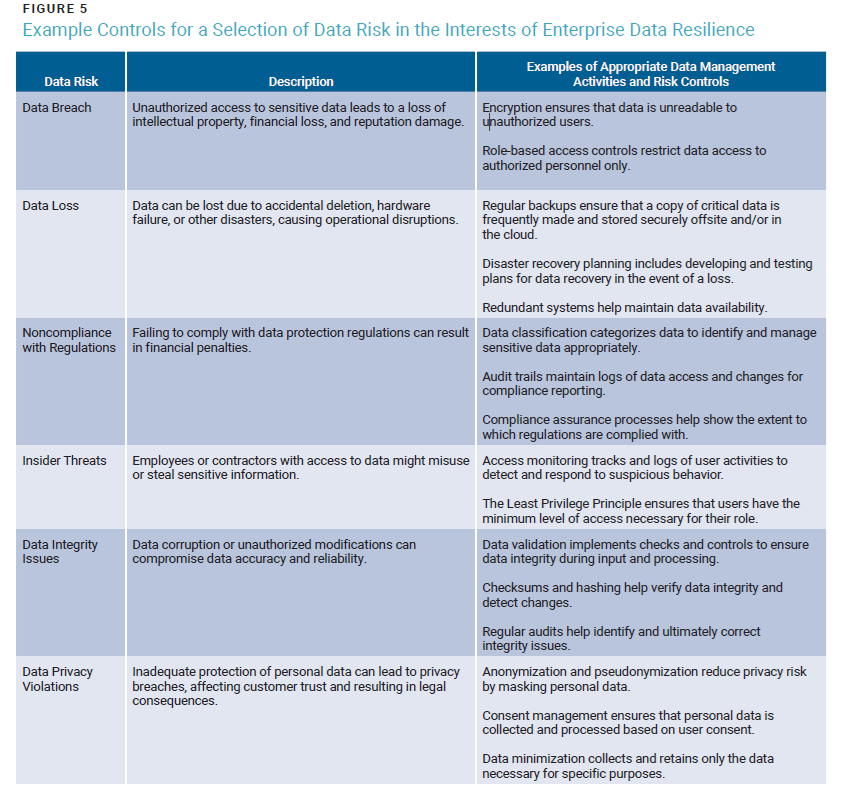
In alignment with good risk management practices, owners of the identified data risk factors should be identified and tasked with monitoring and ensuring that the controls are effective in reducing the risk’s probability and/or impact.
Conclusion
Major banking regulations provide evidence to explain why data risk is a form of enterprise risk. This form of risk is not unique to banking but exists in many different sectors. Looking at a selection of internal enterprise risk illustrates the ways in which the absence of various forms of data management would increase the risk profile of the enterprise. Examining two specific aspects of data management in more detail—data quality and metadata—helps to explain the nature of the risk factors for which these data management activities should serve as controls. These two aspects, along with thoughtful consideration of data resilience, help cement the proposition that data risk equals enterprise risk.
Endnotes
1
Basel Committee on Banking Supervision, “Principles for Effective Risk Data Aggregation and Risk Reporting,” Bank for International Settlements, January 2013,
https://www.bis.org/publ/bcbs239.pdf
2 Basel Committee on Banking Supervision, “Principles for Effective Risk”
3 Deloitte, “The Evolving Role of the Chief Data Officer in Financial Services: From Marshal and Steward to Business Strategist,” 2016, https://www2.deloitte.com/content/dam/Deloitte/uy/Documents/strategy/gx-fsi-evolving-role-of-chief-data-officer.pdf
4 Pearce, G.; “Real-World Data Resilience Demands an Integrated Approach to AI, Data Governance and the Cloud,” ISACA® Journal, vol. 3, 2022, https://www.isaca.org/archives
5 Pearce, G.; “Three Lessons From 100 Years of Data Management,” ISACA®Journal, vol. 4, 2023, https://www.isaca.org/archives
6 Risk Management Team, “How to Prepare for Internal Risk Vs. External Risk,” ComplianceBridge, 8 November 2022, https://compliancebridge.com/internal-risk/
7 Risk Management Team, “How to Prepare for Risk”
8 Segal, E.; “The 9 Biggest Risks and Threats that Companies Will Face in 2024,” Forbes, 3 December 2023, https://www.forbes.com/sites/edwardsegal/2023/12/03/the-8-biggest-risks-and-threats-that-companies-will-face-in-2024/?sh=3bc7c1475f4e
9 Spacey, J.; “22 Examples of Internal Risks,” Simplicable, 21 May 2022, https://simplicable.com/en/internal-risks
10 Chen, R.; “The History, Evolution and Future of Data Quality,” LinkedIn, 23 July 2023, https://www.linkedin.com/pulse/history-evolution-future-data-quality-ramon-chen/
11 Gates, S.; “5 Examples of Bad Data Quality in Business—And How to Avoid Them,” Monte Carlo, 27 September 2023, https://www.montecarlodata.com/blog-bad-data-quality-examples/
12 Pearce, G.; “Data Interoperability: Addressing the Challenges Placing Quality Healthcare at Risk,” ISACA®Journal vol. 2, 2024, https://www.isaca.org/archives
13 Pearce, “Data Interoperability”
14 KeAi Communications, “Why Digital Transformation Projects Fail and How Data Architecture Can Help,” Tech Xplore, 7 September 2022, https://techxplore.com/news/2022-09-digital-architecture.html
15 Bajo, A.; “Understanding Data Quality Issues and Solutions,” Datafold, 2 March 2023, https://www.datafold.com/blog/data-quality-issues16 Porter, A.; “A Guide to Types of Sensitive Information,” BigID, 5 May 2023, https://bigid.com/blog/sensitive-information-guide/
17 Pearce, G.; “Data Resilience Is Data Risk Management,” ISACA®Journal, vol. 3, 2021, https://www.isaca.org/archives
GUY PEARCE | CGEIT, CDPSE
Has served in strategic leadership and governance roles in sectors including banking and healthcare. He has led digital transformations involving IT and data for most of his career, focusing on building sustainable enterprise capability to fully enable them. An industry thought leader with over 100 published articles, he received the 2019 ISACA® Michael Cangemi Best Author award for contributions to IT governance. He serves on the ISACA Ottawa Valley Chapter board in Ontario, Canada.