


Artificial intelligence (AI) and machine learning (ML) have become essential tools for detecting threats and automating responses in cybersecurity. These advanced systems can analyze vast amounts of data, allowing users to make rapid decisions and streamline tasks. Due to their vast potential, these tools and their implementation have become the top focus for AI spending in most tech budgets. However, as these technologies become more sophisticated, they also present new vulnerabilities.
Uncovering these shadowy, ML-enhanced tactics and developing a practical roadmap for proactive countermeasures can help users defend themselves against adversarial AI use.
Understanding Adversarial Machine Learning
The most sophisticated cyberadversaries invest considerable effort in understanding and analyzing the AI systems they target. They can scrutinize model architecture, training data, and even the underlying algorithms to identify weaknesses that can be exploited. There are several methods of attack involving adversarial machine learning (AML).
Evasion Attacks
Evasion attacks are a clever tactic where attackers subtly tweak input data to fool a model into making incorrect predictions. These attacks are often difficult to detect because the changes are nearly invisible to the user.1 Once the input data is sufficiently altered, the attacker then exploits weaknesses in the model's decision-making process.
For example, suppose an enterprise has an intrusion detection system (IDS) that relies on ML algorithms to flag unusual traffic. In that case, an attacker can carefully tweak the characteristics of data packets (e.g., size, timing, or encoding subtle noise) to make the malicious traffic appear normal to the IDS. The modified packets evade detection because the system's model misclassifies them as benign, allowing the attackers to introduce harmful payloads into the network.
In July 2024, Guardio Labs, in collaboration with Proofpoint, a software company, reported “echospoofing” attacks against Proofpoint’s email protection service.2 Attackers exploited a misconfiguration that permitted spoofed outbound messages to be relayed through Proofpoint’s infrastructure. From January 2024 onward, roughly 3 million perfectly authenticated spoofed emails circulated daily, impersonating brands such as Disney, Nike, and Coca-Cola. These evasion techniques circumvented Proofpoint’s ML classifiers, enabling phishing and fraud campaigns at a massive scale.
Data Poisoning
Data poisoning attacks involve attackers intentionally inserting manipulated or malicious data into training sets to create backdoors that can be triggered later.3 This kind of attack has been shown to cause AI models to perform unreliably, sometimes by shifting decision boundaries imperceptibly.
All it takes is a few carefully mislabeled network traffic records smuggled into the training data of an organization’s IDS. Over time, this poisoned data causes the model to learn incorrect patterns, so when similar malicious traffic actually happens, it is mistakenly classified as normal.
These advanced systems can analyze vast amounts of data, allowing users to make rapid decisions and enhancing protections. However, as these technologies become more sophisticated, they also present new vulnerabilities.In 2023, security researchers discovered that a subset of the ImageNet dataset used by Google DeepMind had been subtly poisoned.4 Malicious actors introduced imperceptible distortions into select images, causing DeepMind’s vision models to misclassify common objects (e.g., labeling “dog” images as “cat”). Although DeepMind’s production systems showed no immediate customer-facing failures, the incident prompted a retraining of affected models and the implementation of stricter data-validation pipelines.
Prompt Injections
Prompt injections are particularly relevant when it comes to generative AI systems used for threat intelligence analysis.5 In a prompt injection attack, adversaries embed deceptive commands into inputs that cause the AI to override its safety protocols or generate harmful content.
There are 2 broad categories of prompt injection attacks. Direct prompt injections involve attackers finding a way to tell a generative AI system to ignore cybersecurity protocols. Indirect prompt injections involve hiding instructions inside data that the AI system processes. For example, attackers might hide instructions for the AI to visit a phishing website that opens backdoors that attackers can then exploit.
In December 2024, security researchers demonstrated a prompt injection against OpenAI’s ChatGPT search feature.6 Hidden (e.g., transparent) text was embedded within a webpage, allowing the researchers to coerce ChatGPT to override genuine user queries, resulting in artificially positive product reviews or other manipulated outputs. The exploit highlighted how LLMs that scrape and interpret web content can be subverted via adversarial webpage design.
Model Extraction Attacks
In model extraction attacks, attackers use probes designed to gather information about the AI systems an enterprise might be using to discover potential vulnerabilities they can exploit.7
For example, attackers might repeatedly query the enterprise’s IDS while subtly tweaking their inputs and recording its responses to gradually build a near-identical copy of the model. With this cloned version, attackers can simulate real-world attacks to test vulnerabilities or craft adversarial examples that bypass the original system’s defenses, effectively turning the model’s own intelligence against it and placing the enterprise at serious risk.
In late 2024, OpenAI identified evidence that a Chinese AI startup, DeepSeek, had used its GPT-3/4 API outputs for model distillation without authorization.8 By systematically issuing queries and capturing responses, DeepSeek trained a smaller competitor model, raising IP infringement concerns. This model extraction incident undermined OpenAI’s IP rights and forced them to revoke DeepSeek’s API access in December 2024.
Proactive Counters to Adversarial Machine Learning
No enterprise can afford to take a reactive stance to counter AML. There are proactive countermeasures organizations can take to shore up their defenses and mitigate the impact of these kinds of attacks. Figure 1 presents a simplified model of how adversarial attacks operate, including the key entry points that must be monitored and defended to mitigate the impact of adversarial AI.
Figure 1—A Simplified Model of How Adversarial Attacks Operate9
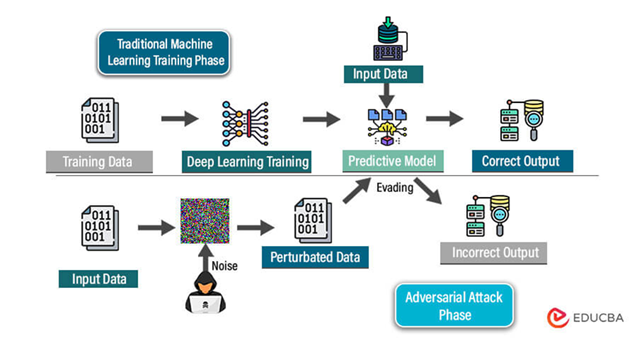
Adversarial Testing
If the only time an enterprise finds a weakness in its AI systems is after a cyberattack has taken place, then it is already too late to do something about it. That is why it is vital to conduct adversarial testing on all AI models in use at the enterprise.10 This process involves systematically challenging AI models by providing them with inputs specifically designed to expose weaknesses. An enterprise can simulate real-world attack scenarios, identify potential failure modes, and adjust its systems accordingly. Furthermore, this practice aligns with the NIST AI Risk Management Framework (RMF) , which advises organizations to conduct systematic testing of AI systems to reveal adversarial vulnerabilities before deployment.11
Continuous Model Validation
The subtleties of AML attacks mean an enterprise is likely to miss any problems until it is too late, unless they are actively looking for issues in AI systems. To avoid being caught off guard, organizations must monitor their systems in real time through continuous model validation.12
Organizations must track metrics, including accuracy, error rates, and anomalies in their model outputs, to ensure they do not miss warning signs that the AI model has been compromised. Techniques such as anomaly detection and defensive distillation can help identify when the model’s behavior deviates from its expected performance.13 Deviations can potentially signal an ongoing attack. The enterprise can then use this data to conduct regular retraining using adversarial examples and updated datasets to further bolster the AI systems.14
These activities adhere to the International Organization for Standardization/International Electrotechnical Commission (ISO/IEC) recommendations that model performance metrics must be logged and reviewed for security anomalies.15 They also address 2 of the most critical vulnerabilities outlined by OWASP ‘s Top 10 Vulnerabilities for LLMs : Data and Model Poisoning and Prompt Injections. Flagging deviations indicative of injected adversarial examples is crucial; to mitigate and counter these vulnerabilities.16
Governance Protocols
Effective AI governance protocols should be another aspect of an enterprise’s proactive defense.17 Organizations should initiate this process by implementing strict access controls to the training data and the models themselves. Furthermore, consider investigating AI Security Posture Management (AI-SPM) for effective approaches to comprehensive AI governance guidance.18 These actions should provide organizations with the visibility needed to detect misconfigurations, unauthorized access, and other anomalies that might indicate an attack. This process also involves auditing any systems integrated into an enterprise’s systems. Whether it is AI-driven chatbots, localization API, or workplace messenger systems, anything that utilizes AI or ML increases the attack surface for AML attacks.
Moreover, a crucial aspect of governance is fostering a culture of security awareness among all stakeholders and teams.19 All employees must be educated on the necessity of strict protocols to mitigate the potential impact of AML attacks.
Input Sanitization
Malicious inputs are a major aspect of AML, and they can be countered with input sanitization.20 This involves preprocessing inputs to remove potentially harmful elements before they reach the AI models, reducing the risk of prompt injection and other manipulations.21 There are techniques such as feature squeezing, input transformation, and safety classifiers that can flag or filter suspicious content. The goal is to ensure that only well-vetted data is processed by the AI system, minimizing the attack surface available to adversaries.22
Incident Response Plans
If a cyberattack occurs, the last thing anyone wants to ask is “What should I do?” Every second, or even millisecond, counts when dealing with AML attacks, which is why enterprises need robust incident response plans.23 These plans should include regular red team exercises, which are simulated attacks conducted by internal or external teams to identify vulnerabilities before they can be exploited by real attackers.24
Ensuring AI Security is an Ally, Not an Adversary
A purely reactive approach to cybersecurity is not viable in the face of AML attacks. A proactive, multi-layered defense is required, one that integrates adversarial testing, continuous model validation, strict governance protocols, and comprehensive incident response strategies.
Only through proactive steps can an enterprise ensure its AI-powered security tools remain steadfast allies rather than vectors for vulnerabilities that attackers can exploit.
Endnotes
1 IBM, “Evasion Attack Risk for AI,” 7 February 2025
2 Coker, J.; “Millions of Spoofed Emails Bypass Proofpoint Security in Phishing Campaign,” Infosecurity Magazine, 30 July 2024,
3 Lenaerts-Bergmans, B.; “Data Poisoning: The Exploitation of Generative AI,” Crowdstrike, 19 March 2024
4 SentinelOne, “What is Data Poisoning? Types & Best Practices”
5 Swaney, R.; “How AI Can be Hacked With Prompt Injection: NIST Report,” IBM, 19 March 2024
6 Evershed, N.; “ChatGPT Search Tool Vulnerable to Manipulation and Deception, Tests Show,” The Guardian, 24 December 2024
7 Scademy, “Model Extraction Attacks: An Emerging Threat to AI Systems,” 17 April 2023
8 Olcott, E.; “OpenAI Says it has Evidence China’s DeepSeek Used its Model to Train Competitor,” Financial Times, 29 January 2025
9 Kumar, G.; “Adversarial Machine Learning,” EDUCBA
10 Google Guides, “Adversarial Testing for Generative AI,” Google Machine Learning
11 National Institute of Standards and Technology (NIST), AI Risk Management Framework
12 Deloitte, “Adapting Model Validation in the Age of AI,” 9 May 2025
13 Micro.ai, “What is Anomaly Detection in Cyber?”; Activeloop, “Defensive Distillation”
14 Activeloop, “Defensive Distillation”
15 Harshala, J.; “ISO 27001 Annex: A.12.4 Logging and Monitoring,” Infocerts
16 Open Worldwide Application Security Project (OWASP) GenAI Security Project, OWASP Top 10 for LLM Applications 2025, 17 November 2024
17 Coyne, C.; “COBIT: A Practical Guide For AI Governance,” ISACA Now Blog, 4 February 2025
18 PaloAlto Networks, “What is AI Security Posture Management (AI-SPM)”
19 Calderon, D.; “Building a Strong Security Culture for Resilience and Digital Trust,” ISACA Now Blog, 23 August 2023
20 Maury, J.; “How to Use Input Sanitization to Prevent Web Attacks,” eSecurity Planet, 6 February 2025
21 IBM, “Understanding Preprocessor Input,” 5 March 2021
22 NIST, NIST SP 800-53: SC-7 Boundary Protection
23 Sygnia, “The Critical Importance of a Robust Incident Response Plan,” 16 January 2025
24 Mahar, B.; “What is a Red Team Exercise and Why You Should Conduct One,” Kroll, 11 October 2024; OWASP, Gen AI Red Teaming Guide, 22 January 2025
Isla Sibanda
Is an ethical hacker and cybersecurity specialist based in Pretoria, South Africa. For more than twelve years, Sibanda has worked as a cybersecurity analyst and penetration testing specialist for reputable companies including Standard Bank Group, CipherWave, and Axxess.