



AI and generative AI are fast becoming essential requirements for any organization to increase its productivity and research capabilities across the globe. AI tools are increasing in number day by day and the latest in line are AI browsers which can not only search the web but also use the web and perform actions on your behalf. While these multifarious functionalities are intended to make users’ lives easier and more productive, these tools can also bring in serious cyber threats and vulnerabilities. This blog will address the importance of securing generative AI, LLMs and agentic AI.
Generative AI vs LLM vs Agentic AI
What is Generative AI?
Generative AI is any machine learning model capable of creating output after it has been trained on large datasets, including text, images or other types of information. GenAI can create novel content in the form of text, images, music, audio and video by learning patterns from existing data. It can even create new lines of code to assist a software developer. A prime example of GenAI is implementing chatbots for customer service and technical support.
What is LLM?
A Large Language Model (LLM) is a form of Gen AI that specializes in processing and generating text-based output. LLMs are trained on massive datasets of text, enabling them to understand and generate patterns in human language. The most well-known example of an LLM is Open AI’s “GPT” series, the latest of which is GPT-5. The acronym “GPT” stands for “Generative Pre-trained Transformer.”
What is Agentic AI?
Agentic AI refers to AI systems that go beyond passive data processing to actively pursuing objectives with minimal human intervention. The characteristics of agentic AI are autonomous action, dynamic decision making, goal-oriented behavior, proactive resource gathering and self-improvement through feedback. Examples of agentic AI include autonomous vehicles, supply chain management systems, automated customer support and IT troubleshooting agents.
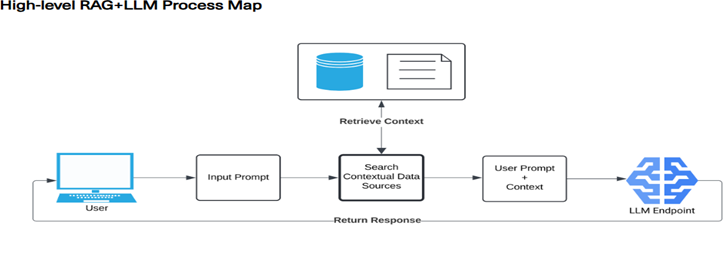
Image source: The Alan Turing Institute
The user issues an input prompt. The model first queries internal knowledge bases such as databases, internal documents, and then the internet to find the relevant information based on a user’s query. The retrieved information is then integrated and provided in context to the LLM which uses both its internal knowledge and the newly provided external information to generate a final, more informed, and contextualized answer.
OWASP Top 10 for LLMs and Generative AI Applications 2025
The Open Web Application Security Project (OWASP) has published Version 2025 of the top 10 risks and vulnerabilities for LLMs and generative AI applications on 18 November 2024. It is reproduced below in brief along with preventive and mitigation strategies.
1. Prompt Injection
Prompt injection vulnerability occurs when a user manipulates the LLM’s behavior or output in unintended ways. The inputs can affect the model even if it is not human-visible or readable as long as the content is processed by the model. Jailbreaking is a form of prompt injection where the attacker provides the inputs that causes the model to disregard its safety protocols entirely. There are two types of prompt injection vulnerabilities.
- Direct prompt injections: Occurs when a user’s prompt input directly alters the behavior of the model in unintended or unexpected ways.
- Indirect prompt injections: Occurs when an LLM accepts input from external sources such as websites or files, which alters the behavior of the model in unintended or unexpected ways.
The consequences of prompt injection vulnerabilities are:
- Disclosure of sensitive information including that of AI systems
- Incorrect or biased outputs
- Manipulating critical decision-making processes
Prevention and Mitigation Strategies:
Provide specific instructions about the model’s role, capabilities, and limitations
- Specify clear output formats
- Implement input and output filtering
- Enforce least privilege and strict access control
- Require human approval for high-risk action
Here is an example of separation of system prompt and user instruction:

2. Sensitive Information Disclosure
Examples of sensitive information disclosure are as follows:
- Leakage of Personally Identifiable Information (PII) during interaction with an LLM
- Proprietary algorithm exposure
- Sensitive business data disclosure
Prevention and Mitigation Strategies:
- Implement data sanitization to prevent user data from entering the training model
- Robust input and strict access control
3. Supply Chain
Creating LLMs is a specialized task that often depends on third-party models which opens to vulnerabilities like that of outdated or deprecated components. AI development often involves diverse software and dataset licenses, creating licensing risks if not properly managed. Unclear terms and conditions and data privacy policies of the model operators can lead to legal and litigation risks.
Prevention and Mitigation Strategies:
- Use only trusted suppliers, after vetting their terms and conditions and privacy policies
- Check for vulnerable and outdated components by vulnerability scanning and regular patching
- Apply comprehensive AI red teaming and evaluations when selecting a third-party model
- Create an inventory of all types of licenses involved using bill of materials and conduct regular audits
- Encrypt models deployed and use vendor attested APIs
4. Data and Model Poisoning
Occurs when pre-training, fine-tuning or embedded data is manipulated to introduce vulnerabilities.
Prevention and Mitigation Strategies:
- Track data origins and verify data legitimacy
- Vet data vendors and validate model outputs against trusted sources
- Limit model exposure to unverified data sources
5. Improper Output Handling
Refers to insufficient validation, sanitization, and handling of the outputs generated by LLMs before being passed to other components.
Prevention and Mitigation Strategies:
- Adopt a zero-trust approach and apply proper input validation
- Implement context-aware output encoding based on where the LLM output will be used
- Employ strict Content Security Policies (CSP) to mitigate the risks of XSS attacks from LLM content
6. Excessive Agency
In simple words, this could be excessive functionality or permissions or excessive autonomy.
Prevention and Mitigation Strategies:
- Ensure LLM agents are allowed to call only the minimum necessary agents
- Limit the functions of LLM extensions to the minimum necessary
- Require a human to approve high-impact actions
7. System Prompt Leakage
System prompt should not contain sensitive information that can be discovered.
Prevention and Mitigation Strategies:
- Avoid embedding any sensitive information like API keys, auth keys, user roles in the system prompts
- Implement a system of guardrails outside of the LLM itself
8. Vector and Embedding Weaknesses
Retrieval Augmented Generation (RAG) enhances the relevance of responses from LLM applications by using vector mechanisms and embedding which can present significant security risks.
Prevention and Mitigation Strategies:
- Restrict access and enforce data usage policies
- Implement robust data validation mechanisms
- Review the data set arising from multiple sources
9. Misinformation
Occurs when LLMs produce false or misleading information that appears credible.
Prevention and Mitigation Strategies:
- Using RAG will enhance the reliability of the model outputs
- Fine-tune the model
- Cross verification and human oversight
- Secure coding practices
10. Unbounded Consumption
Occurs when LLMs allow users to conduct excessive and uncontrolled inferences leading to risks such as Denial of Service (DoS) and service degradation.
Prevention and Mitigation Strategies:
- Implement strict input validation to ensure that inputs do not exceed reasonable size limits
- Provide only the relevant information
- Set timeouts and throttling for resource-intensive operations
- Limit queued actions and scale robustly
Security Risks and Remedial Measures for Agentic AI
Unintended, harmful, or policy-violating agent behaviour is a primary security risk for Agentic AI. The key cause could be prompt injection and it can also arise from misalignment or misrepresentation. Agents can also reveal improperly private or confidential information due to data exfiltration.
Prevention and Mitigation Strategies:
Every agent must have a well-defined set of controlling human users. An agent’s permissions should be dynamically aligned with its specific purpose and current user intent, rather than just being statically minimized.
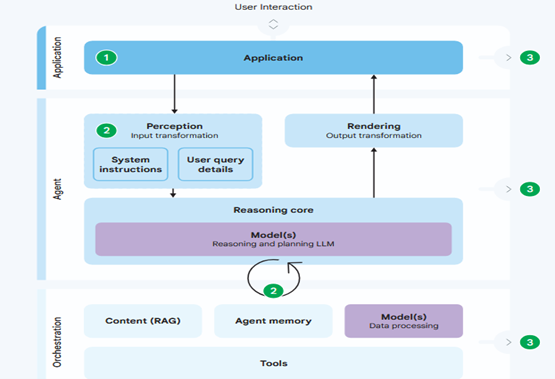
Core principles for Agentic AI security are shown in the above picture.
(1) - Agent user controls
(2) - Agent permissions
(3) - Agent observability
Humans are Necessary for Securing AI
Protective measures from attacks or compromises on AI applications are still currently evolving and human control is mandatory. AI outputs need to be reviewed and checked for accuracy before high impact decisions are taken.
Author’s note: The opinions expressed are of the author’s own views and do not represent that of the organization or of the certification bodies he is affiliated to.
