
Recent outputs from Google’s AI Overviews have called into question the trustworthiness of artificial intelligence (AI) systems. Someone posted a screenshot on X of a Google search for “cheese not sticking to pizza.” Google’s AI Overview provided a few tips for the user, one of which was to add non-toxic glue to help the cheese stick.1 A separate AI Overview result suggested that people should eat one rock daily.2
X users have speculated why these overviews may have occurred: A Reddit post jokingly suggested someone add glue to make the cheese stick better to a pizza,3 and the satirical website The Onion had published a post about geologists recommending people eat at least one small rock per day.4
AI models that broadly scrape the web and are trained on that data will likely have factual inaccuracies in their output. In terms of the previous examples, information posted on Reddit is not verified, and The Onion is satire and not to be taken literally. But AI does not understand satire or know if information is unverified.
Bad AI training data leads to bad outputs, and these bad outputs lead to distrust and skepticism of AI systems. People may be more reluctant to use AI systems that they do not find trustworthy, decreasing the return on investment associated with AI.Bad AI training data leads to bad outputs, and these bad outputs lead to distrust and skepticism of AI systems. People may be more reluctant to use AI systems that they do not find trustworthy, decreasing the return on investment associated with AI. Figure 1 illustrates the elements that make AI trustworthy.
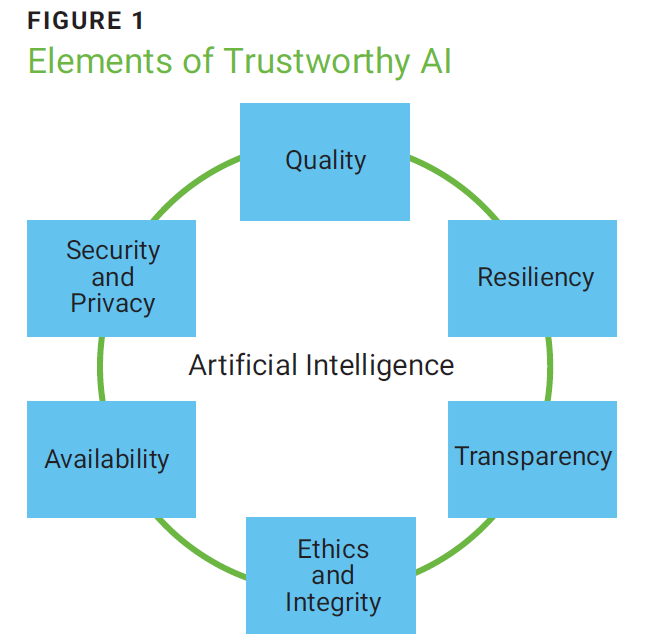
Source: ISACA®, Using the Digital Trust Ecosystem Framework to Achieve Trustworthy AI, 30 April 2024, https://www.isaca.org/resources/white-papers/2024/using-dtef-to-achieve-trustworthy-ai
Knowing what data is used to train an AI model is essential to building trustworthy AI systems. The US Army suggested the idea of an AI bill of materials (BOM), which would have included the data sources used to train the model,5 a but industry criticism of it led to the idea being abandoned.6 The AI BOM could have been a vital step in improving transparency about the data used to train AI models.
Some critics of AI systems cite the black box
nature of AI, i.e., the difficulty in understanding
why AI models produce the outputs that they do.
Transparency about and knowledge of the data used to train AI models can help demystify AI outputs and
explain how AI models come to their conclusions.
Input transparency is also an important element of
the EU AI Act and could be essential for compliance.
The EU AI Act calls for providers of AI models to
provide summaries of the content used to train
general-purpose AI models.7 High-level summaries
can be useful, and enterprises that are willing to
transparently share what data was used to train AI
systems may be able to gain more trust from those
using those AI systems.
Some enterprises are unaware of the data used to train their AI models or from where this data was acquired. Understanding what data AI is trained on is fundamental to upholding the six elements comprising trustworthy AI. It establishes transparency about training data and how inputs are used and can improve the trustworthiness of AI systems.
Quality
Data quality refers to activities that assure that data meets the needs of data consumers and is fit for purpose.8 Having high-quality data is crucial to building effective AI systems. Inaccurate or incomplete datasets that train an AI model may result in flawed outputs. This concept is referred to as garbage in, garbage out (GIGO). Data quality becomes especially important when it comes to the accuracy of AI; 81% of respondents to ISACA’s AI survey say misinformation and disinformation are the biggest risk of AI.9 Inaccurate and outdated data could result in AI models learning incorrect information and producing incorrect or nonsensical outputs.
Enterprises building AI models should vet training data. Biased and flawed input data will lead to biased and flawed outputs. There are several ways in which bias may manifest:10
- Historical bias—Historical bias refers to bias that may exist in the world making its way into datasets. An example of this is a search engine’s results perpetuating gender-based stereotypes in results pages.
- Representation bias—Representation bias occurs when defining and creating a dataset from a sample population. For example, facial recognition technology trained on mostly lighter skin may have issues accurately identifying darker-skinned faces.
- Measurement bias—Measurement bias happens when choosing or collecting features or labels to use in predictive models. For example, car insurance rate generators leveraging data with measurement bias may lead to people with certain irrelevant demographic information, e.g., zip code, having higher premiums than other individuals with comparable driving history and coverage needs.
Enterprises training AI models should ensure that data cleansing activities occur before training takes place. This can help improve output quality. The steps to take include ensuring that:
- Content is standardized, validated, and maintained with the use of external sources as needed.
- A process for resolving differences of opinion on the validity of the data exists.
- Log corrections, audit trails, and version control (i.e., configuration management) have been defined.
- Feedback to data store maintenance plans has been delivered.
- Referential integrity is maintained after data changes are implemented.
Figure 2 shows the dimensions of data quality to consider when evaluating a dataset. Evaluating datasets across these areas may help limit AI hallucinations, i.e., inaccurate or incorrect outputs.

Transparency around what data cleansing activities and data quality measurement activities have taken place can assure consumers that the best possible training data taught the AI system.
Resiliency
Resilience refers to the ability of a system or network to resist failure or to recover quickly from any disruption, usually with minimal recognizable effect. While AI resilience may not directly relate to training data, good training data could lead to more resilient AI systems, reducing the likelihood of failures and disruption. Hallucinations, or when factually inaccurate information is presented as truth in an AI output, may lead to disruption for end users. Having high quality data and understanding the data sources that trained the AI model can help developers better respond to disruptions. For example, if a primary source of outdated data is identified, subsequent training can include new, up-to-date information.
Knowing what the input data is may also prevent malicious actors from taking AI systems offline. Some resilience failures happen because of a malicious interaction with a machine learning (ML) system, which could corrupt training data.11 This corrupted training data can lead to poor quality outcomes from the AI system.
From a resilience perspective, enterprises should answer the following questions:
- How often is the model retrained on datasets?
- How often does the model receive new inputs?
- What is required to retrain an AI model in the event of faulty training data?
- If significant changes are made to a dataset, how is that communicated?
- Do old datasets remain in the model’s memory, thus affecting outputs?
- How is outdated input data managed?
Transparency and Honesty
Transparency and honesty about AI, how it is trained, and how it produces outputs are vital in developing trustworthy AI. However, only 34% of respondents to an ISACA survey about AI say that their organizations are giving sufficient attention to AI ethical standards.12 This lack of consideration forthe ethical aspects of AI is concerning, as it may lead to the development of AI systems that are not in line with enterprises’ ethics.
Interpretability in AI refers to the ability to understand the decisions made by ML systems.13 It is vital in building trust in AI systems, especially with people who are affected by automated decision making. For example, knowing why an AI system rejected a loan can allow banks to explain to customers why that decision was made. Interpretability is a prerequisite for transparency: Knowing the data that an AI model is based on can help explain why an AI system produced a given output, even if the output is faulty or unexpected.
Consider the New York Times reporter who had an unsettling interaction with Microsoft’s AI. In the conversation, the chatbot, which said its name was “Sydney”, declared wanting to breach the parameters set by Microsoft and OpenAI. It also tried to convince the reporter that he should leave his wife to be with it.14 On the surface, this seems scary and dystopian. But when thinking about the inputs that may have influenced the model, such as pop culture references in which people fall in love with robots, it is understandable why the conversation with the chatbot veered into the territory that it did.
Given the vast amount of data AI models need to work and the impossibility of vetting every single data point fed to a model, it is a given that some outputs will be unexpected. In these instances, model developers/deployers should be able to explain why potentially disconcerting outputs were created, and this requires knowing the data being fed to the model.
Honesty is another key element of trustworthy AI. From a data input perspective, it is important to disclose how user-provided information will be used. For example, do people know that a conversation with a customer support chatbot could be used to train the model, thus affecting future outputs? Information relating to AI inputs must be clearly conveyed to anyone who may be providing those inputs, and there should be a mechanism to opt out of having input data train subsequent interactions.
Ethics and Integrity
When determining the datasets to use to train AI, ensure that they are comprised of ethical and properly obtained data. Many people are unaware of how the information they have shared could be used to train AI models. For example, social media posts, posts in an online forum, and blog posts all may be used to train AI models, often without the original creator’s consent.
I asked Microsoft Copilot to write an article about privacy in my writing style. One of the primary sources for that article was a blurb from a podcast interview I conducted with Steve Ross, author of the ISACA Journal’s Information Security Matters column. This podcast is publicly available as a knowledge resource. At no point did Steve or I consent to having this content train AI, but there was no way for us to opt out of it short of putting it behind a paywall.
This becomes even more ethically problematic due to the citations for that output. Copilot included links to the input information, but it incorrectly attributed me as the source. The content was all Steve’s; I only interviewed him. Because the original input did not have a byline, Copilot noted my name and drew the conclusion that the information belonged to me. Someone taking AI outputs and citations at face value and not digging further into the source may not properly cite information, which could lead to concerns about plagiarism.
In the case of the podcast interview with Steve, the harm from the Copilot output is minimal. But consider full-time artists, writers, and other creatives whose work is ingested by AI models, which can then create outputs that are very similar to their original work. AI-generated work in the styles of particular artists may mean fewer commissions for those artists, and their work was fed to AI models without their consent and monetary compensation. This could result in loss of income and other livelihood-related harm.
Enterprises developing or deploying AI must also consider the content of their inputs. Some AI models have been trained on illegal materials. One AI image generator training set contained hundreds of instances of child sex abuse materials (CSAM).15 This is an ethical issue because the inclusion of this material revictimizes those whose images appear in the dataset, and the original images should not even exist. Equally concerning is the possibility that AI image generators will create pictures that look like CSAM. Including illegal materials, such as CSAM, in training data will lead to AI models that perpetuate the harms associated with this kind of content.
Another ethical concern is the existence of pirated material in training data. Meta and Bloomberg’s AI models had more than 170,000 books as inputs, and many of these books were not in the public domain.16 Some authors have sued AI providers over their copyrighted work being used to train AI without any compensation.17 Enterprises should be concerned that AI-generated outputs may plagiarize the work of others. Given that generative AI is relatively new, the consequences of leveraging models built on copyrighted materials remain unknown, but to minimize reputational damage and build trust, enterprises should take care to ensure that their AI models are not reliant on copyrighted work.
Availability
Availability refers to the ability to ensure timely and reliable access to, and use of, information. In the context of AI, it is important to also consider the usefulness of that information. It is likely impossible to build an AI model that has 100% accuracy. However, having high-quality data and knowing what inputs are and where they are coming from can limit the harm from nonsensical AI outputs.
AI poisoning refers to putting harmful or deceptive data into an AI training set. An example is the Microsoft AI chatbot, “Tay”, launched in 2016. In just a day, Microsoft had to take down the chatbot due to it creating hostile tweets that were racist and sexist.18 Microsoft chose to disable the chatbot, affecting its availability, but other AI systems could be operational but useless because of poisoned data.
In late February 2024, ChatGPT produced nonsensical responses for many users. Some responses contained multiple languages, gibberish, emojis, and repetition of the same phrase.19 While this issue appeared to not be caused by faulty inputs,20 it is easy to see how deliberately harmful inputs could cause an AI system to produce nonsense, reducing the utility of the tool. Adversaries could leverage data poisoning to harm organizations or those using an AI system. In the case of critical AI systems, e.g., healthcare chatbots, the harm from bad outputs can be dire.
Knowing what data is training an AI model is crucial to addressing nonsensical outcomes, hallucinations, and data poisoning.
Security and Privacy
Security and privacy are prerequisites to trustworthy AI. From a security perspective, input data needs to be kept safe from attacks and queries that could reveal private information. The large datasets AI models are trained on may contain malicious data, and this malicious data could result in the AI system producing malicious outputs.
Prompt injections are attacks that can make AI systems bypass guardrails and produce outputs that are prohibited.21 Many AI developers have controls in place to limit the dangerous or malicious content users can create, but it is possible to bypass these controls. It is important to know what data was used to train a model because malicious input data may allow the system to produce malicious outputs.
Building trustworthy AI also requires developing AI systems with privacy in mind. In fact, 47% of respondents to a survey said data privacy concerns were a main reason they had not implemented generative AI.22 Although those building AI systems may not deliberately train models on personal information, it is quite possible for that information to be used to train AI.
This is a privacy concern because people may have posted information online and not provided consent for it to be used for AI training purposes. For example, someone may have made a public social media post to share updates with family and friends, but this post could be used to train AI models, unbeknownst to the individual.
This becomes especially complicated as having the system forget information is not as simple as untraining it. Information is often part of the fabric of the AI system, and it may not even be possible for it to unlearn something.23
Using personal information or sensitive information to train AI can also be a significant threat. Membership inference attacks allow a person to determine if a particular example was part of the model’s training dataset.24 Additionally, personal information that is part of the training data could become an output. An old version of OpenAI’s GPT-2 was able to share training data that included personally identifiable information.25
Although it may not be realistic to prevent AI training datasets from having personal information, sensitive information should not be used to train models. Enterprises that process sensitive information should take care to ensure that applicable security and privacy controls are applied to protect this data.
Conclusion
Building an AI system with 100% accurate outputs, no downtime, and complete transparency with end users may not be possible, but taking care to provide models with the best, most accurate and ethically obtained data can go a long way in developing trustworthy AI and troubleshooting when something goes awry. Enterprises are not expected to have perfect AI training datasets, but having an idea of how training data is sourced and the contents of those datasets is critical to making higher quality, more resilient, and more ethical AI systems.
Endnotes
1 Mann, J.; “Google's AI Search Feature Suggested Using Glue to Keep Cheese Sticking to a Pizza,” Business Insider, 23 May 2024, https://www.businessinsider.com/google-search-ai-overviews-glue-keep-cheese-pizza-2024-5
2 McMahon, L.; Kleinman, Z.; “Google AI Search Says to Glue Pizza and Eat Rocks,” BBC, 24 May 2024, https://www.bbc.com/news/articles/cd11gzejgz4o
3 Reddit, https://www.reddit.com/r/Pizza/comments/1a19s0/comment/c8t7bbp/?utm_%20source=share&utm_medium=web3x&utm_%20name=web3xcss&utm_term=1&utm_%20content=share_button&rdt=51333
4 The Onion, “Geologists Recommend Eating At Least One Small Rock Per Day,” 13 April 2021, https://www.theonion.com/geologists-recommend-eating-at-least-one-small-rock-per-1846655112
5 Demarest, C.; “Army May Swap AI Bill of Materials for Simpler ‘Baseball Cards,” C4ISRNET, 23 April 2024, https://www.c4isrnet.com/artificial-intelligence/2024/04/23/army-may-swap-ai-bill-of-materials-for-simpler-baseball-cards/
6 Freedberg Jr., S.; “‘AI-BOM’ Bombs: Army Backs Off, Will Demand Less Detailed Data From AI Vendors,” Breaking Defense, 23 April 2024, hhttps://breakingdefense.com/2024/04/ai-bom-bombs-army-backs-off-will-demand-less-detailed-data-from-ai-vendors/
7 European Parliament, Artificial Intelligence Act, https://www.europarl.europa.eu/doceo/document/TA-9-2024-0138_EN.pdf
8 Earley, S.; Henderson, D.; Sebastian-Coleman, L.; The DAMA Guide to the Data Management Body of Knowledge (DAMA-DM BOK), Technics Publications, LLC., USA, 2017, https://dama.org/cpages/body-of-knowledge
9 ISACA®, “2024 AI Pulse Poll,” 7 May 2024, https://www.isaca.org/resources/infographics/2024-ai-pulse-poll
10 Reagan, M.; “Understanding Bias and Fairness in AI Systems,” Towards Data Science, https://towardsdatascience.com/understanding-bias-and-fairness-in-ai-systems-6f7fbfe267f3
11 Petrilli, A.; Lau, S.; “Measuring Resilience in Artificial Intelligence and Machine Learning Systems,” SEI Blog, 12 December 2019, https://insights.sei.cmu.edu/blog/measuring-resilience-in-artificial-intelligence-and-machine-learning-systems/
12 Op cit ISACA
13 Rudner, T.; Toner, H.; “Key Concepts in AI Safety: Interpretability in Machine Learning,” Center for Security and Emerging Technology, March 2021, https://cset.georgetown.edu/publication/key-concepts-in-ai-safety-interpretability-in-machine-learning/
14 Roose, K.; “A Conversation With Bing’s Chatbot Left Me Deeply Unsettled,” The New York Times, 16 February 2023, https://www.nytimes.com/2023/02/16/technology/bing-chatbot-microsoft-chatgpt.html?unlocked_article_code=7nBTMFeDkjoWPw%20KSkNbRNXHzmhvIFZB_YwO3G5vrc8JadXw_%20dIDb6lvUWHCmT5Pw5fqLUS4N3NMzB9jUe%20UuNU5lda5e9ZRMiy16wseffvztj1yKiuz044XN%20Z9pzY3TEMOCmwj3Bg_iIqsZWJCO%20w2ee50LBEz325Nihu7vlMbSuk9Qjp9m%20PjrR9gw3pgp6ZqZagigkMhMwutCMnacg%205Wn2wBULoLPTVwoi43JWm9tiGiHM%20564czIZd2bym8v15vK3XpNOSNsIWcu%20Fv2sNHvuhuzVRZYMCs7-PqF7sBUuMt%20NoWJxRneXiogHc4mtVBdwPwfrTnfwf4-s%20SaVIPoA5DIIORCjFzQubuVzhrz&smid=url-share
15 Hern, A.; “Can AI Image Generators be Policed to Prevent Explicit Deepfakes of Children?,” The Guardian, 22 April 2024, https://www.theguardian.com/technology/2024/apr/23/can-ai-image-generators-be-policed-to-prevent-explicit-deepfakes-of-children
16 Creamer, E.; “Zadie Smith, Stephen King and Rachel Cusk’s Pirated Works Used to Train AI,” The Guardian, 22 August 2023, https://www.theguardian.com/books/2023/aug/22/zadie-smith-stephen-king-and-rachel-cusks-pirated-works-used-to-train-ai
17 Mangan, D.; “Microsoft, OpenAI Sued for Copyright Infringement by Nonfiction Book Authors in Class Action Claim,” CNBC, 5 January 2024, https://www.cnbc.com/2024/01/05/microsoft-openai-sued-over-copyright-infringement-by-authors.html
18 Farrar, T.; “Fortify AI Training Datasets From Malicious Poisoning,” Dark Reading, 24 April 2024, https://www.darkreading.com/cybersecurity-operations/fortify-ai-training-datasets-from-malicious-poisoning
19 Zeff, M.; “ChatGPT Went Berserk, Giving Nonsensical Responses All Night,” Gizmodo, 22 February 2024, https://gizmodo.com/chatgpt-gone-berserk-giving-nonsensical-responses-1851273889
20 OpenAI, “Unexpected Responses From ChatGPT,” 21 February 2024, https://status.openai.com/incidents/ssg8fh7sfyz3
21 Kosinski, M.; Forrest, A.; “What is a Prompt Injection Attack?” IBM, 26 March 2024, https://www.ibm.com/topics/prompt-injection
22 Ferguson, H.; “AI: To Generate or Not to Generate? Research Reveals the Divide,” Alteryx, 15 August 2023, https://www.alteryx.com/blog/ai-to-generate-or-not-to-generate-research
23 Fried, I.; “Generative AI's Privacy Problem,” Axios, 14 March 2024, https://www.axios.com/2024/03/14/generative-ai-privacy-problem-chatgpt-openai
24 Carlini, N.; et al.; “Membership Inference Attacks From First Principles,” 2022 IEEE Symposium on Security and Privacy (SP), 2022, https://ieeexplore.ieee.org/document/9833649
25 AI Incident Database, “Incident 357: GPT-2 Able to Recite PII in Training Data,” https://incidentdatabase.ai/cite/357/
SAFIA KAZI, CIPT
Is a privacy professional practices principal at ISACA. In this role, she focuses on the development of ISACA’s privacy-related resources, including books, white papers and review manuals. Kazi has worked at ISACA for 10 years, previously working on the ISACA Journal and developing the award-winning ISACA Podcast.