
In the evolving landscape of cybersecurity, accurately measuring control strength is essential for understanding and mitigating risk. The widely accepted risk equation, Inherent Risk - Control Strength = Residual Risk , serves as a foundational approach for calculating remaining exposure.1 However, this model has limitations when applied in real-world settings. By examining control strength in multidimensional terms, security professionals can achieve a more nuanced understanding of how controls function, both in isolation and as part of a broader risk management strategy.
Understanding Inherent and Residual Risk
Before evaluating how to measure control strength, it is important to understand why it should be measured in the first place. From a cyberrisk perspective, this means evaluating the relevance of the fundamental risk equation:
Inherent Risk - Control Strength = Residual Risk
The equation assumes that the remaining risk is based on the initial risk and the effectiveness of the controls being used. This interpretation is prevalent in a variety of sources and generally represents the collective understanding of most practitioners.2
In this interpretation, inherent risk represents the level of risk faced by an organization without any controls, serving as a baseline for recognizing the scope of exposure without countermeasures. In this way, inherent risk is a hypothetical construct—an idealized state of vulnerability that is challenging to measure directly. Residual risk, conversely, is the risk that remains after applying controls, and the differential between these two figures represents the value added by the controls. The assumption in this approach to measuring risk is that one cannot measure present state risk directly; thus, the equation is used to derive the current state of risk exposure (although some also think of residual risk as a future state). This mindset can lead to several problems.
First, it is troublesome to assume that it is easier to measure risk posture from the theoretical past when no controls were implemented. Conversely, the state of the organization’s risk posture is on display and evident to those looking at and managing it today. Second, it assumes that it is possible to deploy technologies without any controls. Remember, the equation is absolute; it does not refer to “mostly no controls” or “without recent controls.” It refers to no controls, and that means absolutely zero defenses or recovery capabilities. The technologies one may deploy will inherently have controls baked into them, either via solid coding practices or the migration of optional features into base features.3 This means that organizations must either 1) add a parameter that reduces base security features back to an insecure state or 2) accept the inaccuracy in measurement.
Justifications for this equation typically fall into two camps. The first adopts the logic of “Do it that way because that is how it has always been done.” This shows up in the zeitgeist of cyberrisk management, sometimes with a callback to common security certifications where the aforementioned risk equation is taught. This ipso facto logic fails to examine the points raised here.4
The second justification is more specious. In this rationalization, the argument is that the cyberrisk team should be credited for the work that was done to improve the cyberrisk posture. The reasoning is that it is important that the audience of these reports sees how damaging it could have been if they had failed to act. Two issues exist with this approach. First, it presumes that no credit has been previously allocated to the teams that existed when the technologies were implemented. The second and most important is that it presupposes that current management cares about what was previously done. The fundamental mismatch is between what the risk team needs and what the management team needs. Namely, the self-serving nature of gaining credit for work done in prior periods versus the need for actionable forward-looking information about cyber concerns that could impact the organization’s mission.
An alternate perspective on inherent and residual risk is provided by ISACA’s Risk IT Practitioner’s Guide.5 The guide describes current risk and its relationship to inherent and residual risk. According to the guide, inherent risk was from the theoretical past, current risk is precisely what it sounds like, and residual risk is a future state, with some additional control options applied that are under consideration. The addition of a third risk state solves some of the aforementioned problems, namely the relevancy issue, but retains the others. It still includes a starting point of a fictitious zero-controls environment to which one must add current controls to get to the current risk value. Then even more controls are added to get to the future state (assuming a future-looking what-if analysis is being conducted). Mixed usage of a variety of terms adds confusion, since many will think of residual risk as the current state, and others will think of residual risk as the future state. Notably, the diagram in figure 1 has been removed from the newer editions of the Risk IT Practitioner’s Guide, although the concept is still discussed.6
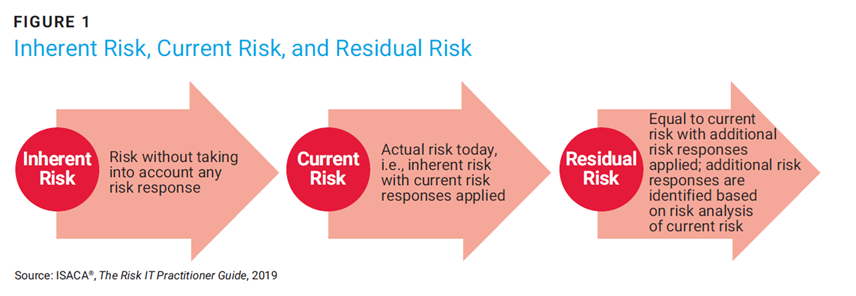
Assuming that one can measure the current state of risk directly and not through derivation, the question arises: Why is control strength needed at all? In the aforementioned example, it is used to answer, “How much less risk will I have if I do x?” In the future risk calculation, it is necessary to measure the relative difference between controls now and in the future. Control strength can also be used when the other two variables in the risk equation (probability and severity) need to be modified to better match reality. The first use case is very straightforward but the second involves adjustments to the parameters necessitated by the models in which the data is being used. For example, a cyberinsurance underwriter will have access to the exact claims paid for various organizations. They may want to introduce a parameter that reflects how much more or less likely it is that an organization would experience claims at a variety of severity levels. In such cases, they may use controls to augment the actual claims data using some ratio based on control efficacy (e.g., -5% for organizations using multifactor authentication [MFA], etc.).7 This is a very specialized example of the future-looking residual risk use case.
How to Build a Control Model
Risk and control models are intended to be parsimonious because they are not building exact replicas of any specific environment. Such modeling makes several assumptions. First, measuring all facets of the target environment is not feasible or economical. Next, the factors being measured should be meaningful representations of the whole. If the model has more variables than are necessary to explain the data collected, then the model is overparameterized. In this case, the model learns not only the true patterns in the data but also the noise. In other words, just because one can measure more parameters does not mean they should, as it could water down the purer signals in the data. A parsimonious control model should strive to be an economic representation of reality.
Gathering data for the model can be done in three ways.8 Consent matters, so in each of these models, one must gather data in a manner that is both legal and permissible. The first approach (external) is to only collect control signals external to an organization. In this way, publicly available systems can be scanned to gather information about an organization from data brokers and other sites that collect data about the organization and its employee’s activities.
The second approach goes deeper into the organization and gathers information from key personnel (self-attestation). This can be achieved through various means, from leveraging structured surveys (e.g., a Standardized Information Gathering (SIG) or SIG Lite questionnaire)9 to the Cloud Security Alliance’s Security Trust Assurance and Risk (STAR) registry.10 Unstructured documents containing security policies or compliance statements can also be consulted. These are unvalidated documents provided directly by the enterprise.
Last, the third approach involves a series of validated documentation that is gathered from the organization either through sampling or empirical testing. Such data is highly relevant, validated, and has high fidelity.
Where one gathers control data depends on what permissions they have, the resources they have with which to measure (e.g., time, staff, tools), the type of decisions they are making, and the data necessary to best support those decisions. In each case, however it is important to note that data from any of these sources better informs risk and control models.11 If one has no existing knowledge of something, even one data point vastly improves their knowledge of it. After deciding where to gather information for a control model, next is the decision of which control strength parameters should be measured.
Maturity is likewise critical for organizations to measure, especially regarding process controls. Where coverage does not quite meet the needs of security processes, maturity certainly will.
Defining Control Strength Parameters
Despite being a single measurement, control strength is a multifaceted construct. In use cases where a single parameter is being measured, the strength is reflective of the ability of the control to keep attackers at bay (or prevent insiders from making mistakes). However, many control strength calculations in use are derived calculations that rely upon one or more parameters:
- Strength—How effectively a control can prevent or mitigate cyberthreats (from external and internal actors, both intentional and accidental)
- Coverage—The extent to which the control is deployed across an organization's infrastructure, establishing a denominator reflecting deployment breadth
- Maturity—The extent to which security controls are consistently implemented, managed, and optimized within an organization to ensure reliable performance over time
- Time—The duration the control has been operational, allowing potential issues to surface and enabling reliability metrics
- Design quality—The degree to which the control aligns with best practices, policies, and procedures, determining if the control’s conceptual foundation is sound
Each parameter contributes a unique perspective, offering insights into different facets of a control’s utility and durability within a cybersecurity framework. However, some variables are better suited to measuring strength than others. First, strength is an absolute must as it denotes the ability of the control to do the very thing it was put in place to do, namely, to prevent bad things from happening and to quickly recover if they do (resilience). Coverage also makes sense, especially for controls that are “things.” It is rare that an organization has uniform control parity across all its systems, so a parameter that reflects the coverage of the controls (at various strengths) is essential. Maturity is likewise critical for organizations to measure, especially regarding process controls. Where coverage does not quite meet the needs of security processes, maturity certainly will. One can also use maturity as a proxy variable for strength with the assumption that a more mature control represents greater strength.
The variables of time and design are often used in operational risk practices but have less value than the other parameters. There is logic in a time variable, representing the length that a control is in place and operating. In this way, time in service gives the organization a chance to uncover any issues, a principle that is well known in quality management.12 However, it is worth evaluating whether this aspect of controls reduces strength or is simply a quality control metric. Ostensibly, if the control is implemented properly, it will have the same strength when implemented as it will a year later, in which case organizations may underestimate the effect it has on risk. Likewise, the organization could also overestimate the risk if it turns out that the control was not implemented correctly. Regardless, this is better addressed through security architecture, testing, and reflecting on any known issues in the strength parameter itself.
Finally, the design variable is meant to identify how well designed the control is with the assumption that a well-designed control has more of an effect on risk than a poorly designed one. It may be evident here, but the inclusion of this control serves to over-parameterize the risk equation by effectively measuring strength twice—once directly and another time through this proxy variable. Likewise, it could serve as another measure of maturity (a better-designed control is likely to also be more mature). No one would want to live in a well-designed but poorly built home, and similarly, no hacker would be repelled by a well-designed but poorly implemented control. Generally, this variable is better suited to the quality management of a security architecture function than a direct measure of control efficacy.
How each of these parameters is measured also requires some consideration. There are generally two well-established scales one can consider for this purpose.13 The first is an absolute scale of good and bad. This is useful when the control being measured has an obvious and widely agreed upon state of “goodness” and “badness.” In other words, use an absolute scale when it is clear what is good and what is bad. An alternate approach is using a relative scale. The relative approach is used when measuring one organization’s control strength against another’s and assessing a relative control strength score based on the difference. This is useful when there is no well-known best state, but it is essential to measure the current state against others. It can be compared to grading on a curve, where the best performers set the mark for the highest score (an A) and the lowest score is the worst (an F). These are typically used for benchmarking.
Designing and Evaluating a Control Efficacy Model
Based on this assessment, most users will want to construct their control ratings based on strength, maturity, and coverage. A simple multiplicative relationship between the effect of coverage on strength is reasonable. The following questions can be used to identify the appropriate parameters, source of data, and scale.
First-Party Control Strength Use Cases
- Are our controls good enough to manage our risk?
- Are our controls suitable for insurance underwriting?
- Do our controls meet our regulatory requirements?
- How do our controls appear to others?
Third-Party Control Strength Use Cases
- How do my controls compare to others?
- Are my suppliers managing their cybersecurity posture well enough?
- Do good cybersecurity controls protect my investment in this organization?
- Do this enterprise’s security controls meet our regulatory requirements?
- Are this enterprise’s security controls suitable for underwriting?
Figure 2 takes these use cases and provides a recommended source of control parameter information and a scale for scoring.
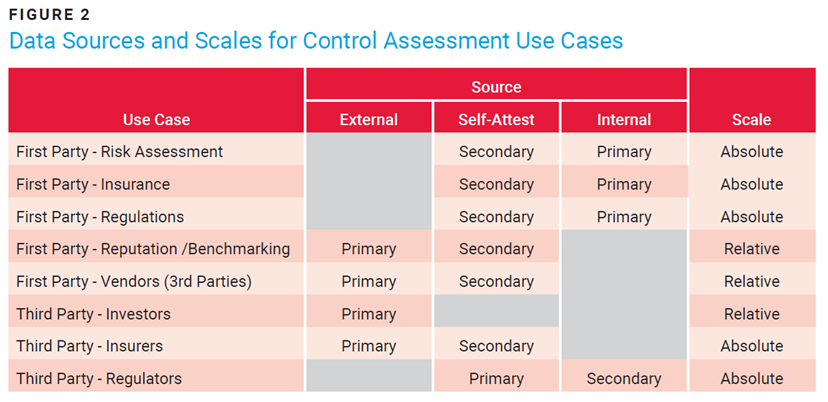
For first-party self-evaluations, data for the three parameters (strength, coverage, maturity) should be gathered from internal sources, either by direct query or via empirical testing. Organizations can rely on secondary self-attestation as needed. These should also be modeled using an absolute scale since there will be internal, approved policies; authoritative sources that are proxies for internal policies (e.g., US National Institute of Standards and Technology [NIST], International Organization for Standardization [ISO]); and/or regulatory requirements.
For a first party concerned about how it is perceived by its clients, or one that manages an extensive portfolio of vendors, the focus should shift to leveraging external control scores and supplementing them with self-attestation as needed. Since this measure is about how alike or unlike they are from their peers, a relative scoring model makes sense.
The next set of use cases focuses on how a series of third parties may view a vast array of enterprises collectively. For example, an investor would want to know how an organization in their portfolio is performing against its peers. That would entail a primarily external-based scoring mechanism with a relative scale. Insurers want a similar view of an organization’s operations (external). Still, they may also want a self-attestation for legal reasons, such as adjudicating control states at the time of a claim. Such scores are typically absolute, governed around a sort of cyber poverty line (e.g., will or will not cover). Finally, during a regulatory audit, the examiners compare both self-attested data and internally gathered artifacts against the absolute scale of compliance (which sometimes means being tested against best practices).
Conclusion
Measuring control strength is complex. Traditional risk models rely on inherent and residual risk calculations, but it is important to question the validity of assuming inherent risk as a baseline, especially in modern environments where few systems are entirely devoid of controls. By introducing concepts such as current risk and a range of parameters such as maturity, coverage, and design quality, a more robust, context-sensitive framework appears.
Different methods of gathering control data—external, self-attested, and validated—enhance the fidelity of control strength assessments. Organizations can use these multidimensional metrics to improve internal and external control assessments, address regulatory requirements, and support third-party evaluations. A holistic approach to measuring control strength equips organizations with actionable insights, enabling a proactive stance against cyberthreats while also providing meaningful, forward-looking data to stakeholders.
Endnotes
1 Chapple, M.; Stewart, J. M.; et al.; ISC2 CISSP Certified Information Systems Security Professional Official Study Guide,10th Edition, Wiley, 2024
2 ISC2, Certified Information Systems Security Professional; ISACA®, Certified in Risk and Information Systems Control® (CRISC® Review Manual, 7th edition, 2023; National Institute of Standards and Technology (NIST), NIST Special Publication (SP) 800-300 Rev. 1—Guide for Conducting Risk Assessments, USA, September 2012
3 Conklin, W. A.; White, G. B.; et al.; Principles of Computer Security: CompTIA Security+ and Beyond, McGraw Hill Education, 2018
4 ISC2, Certified Information Systems; ISACA, Certified in Risk; NIST, SP 800-30 Rev. 1
5 ISACA, The Risk IT Practitioner Guide, 2019
6 ISACA, The Risk IT Practitioner Guide, 2nd edition, 2023
7 Romanosky, S.; Ablon, L.; et al.; “Content Analysis of Cyber Insurance Policies: How do Carriers Price Cyber Risk?,” Journal of Cybersecurity, vol. 5, iss. 1, 2019
8 Freund, J.; Vadala, D.; “Building a Global Cyber Rating - How to Objectively Rate Cyber Capabilities,” RSA Conference 2021
9 Shared Assessments, “SIG Questionnaire”
10 Cloud Security Alliance, CSA STAR Registry, 2023
11 Hubbard, D. W.; How to Measure Anything: Finding the Value of “Intangibles” in Business, 3rd ed., Wiley, 2014
12 Ben-Daya, M.; Kumar, U.; et al.; Introduction to Maintenance Engineering: Modeling, Optimization, and Management, Wiley, 2016
13 Stevens, S. S.; “On the Theory of Scales of Measurement,” Science, vol. 103, iss. 2684, 1946, p. 677-680
JACK FREUND | PH.D., CISA, CISM, CGEIT, CRISC, CDPSE
Is an experienced cybersecurity and governance, risk, and compliance (GRC) professional. He is also the co-author of the foundational cyberrisk quantification (CRQ) book using the FAIR standard, which was inducted into the Cybersecurity Canon in 2016. He was named an ISSA Distinguished Fellow, FAIR Institute Fellow, IAPP Fellow of Information Privacy, ISC2 2020 Global Achievement Awardee, and ISACA’s 2018 John W. Lainhart IV Common Body of Knowledge Award recipient. Freund also serves on the board of the ISSA Education Foundation.


