
Data annotation is an essential technique that enables machines to recognize and categorize objects within images, videos, and text data used in artificial intelligence (AI) applications. This process can be time consuming and resource intensive, which is why crowdsourcing platforms such as Amazon Mechanical Turk (MTurk), Toloka, and ScaleHub provide a means to outsource annotation tasks to a large pool of workers. Many large language models (LLMs) rely heavily on labeled data for training and have a high demand for annotated data, which crowdsourcing can help meet in a flexible and cost-effective manner. However, this approach also comes with several challenges that must be addressed to ensure the quality and accuracy of the annotations. One major challenge is the safety and security of critical data. Organizations possess large sets of data that can be sensitive, and if this data is used for crowdsourcing, it will leave the organization and its customers at risk. It is crucial to explore the challenges, mitigations, and employment of secure infrastructure to elastically meet the data annotation demand through crowdsourcing channels.
Data annotation plays a crucial role in the development of LLMs, conversational AI, and chatbots, as it provides context and categorization for AI models to extract valuable insights from raw data.A large volume of high-quality annotated data is essential to train an AI model to perform a task with accuracy. Data annotation plays a crucial role in the development of LLMs, conversational AI, and chatbots, as it provides context and categorization for AI models to extract valuable insights from raw data. However, meeting the growing demand for annotated data can be challenging, especially with the increasing popularity of LLMs. LLMs are deep learning algorithms that require vast amounts of data for training. These models can perform various tasks—such as text generation, summarization, translation, and content prediction—using large datasets. However, the sheer volume of annotated data required to train these models is enormous, often billions or trillions of data points. To address this challenge, organizations have several options for data annotation: in-house, outsourcing, AI-driven methods, and crowdsourcing. Each method has its advantages and disadvantages, including cost, time, and quality considerations. With the exponential growth of LLM demand, a mix of these methods can be beneficial to meet the demand efficiently.
Crowdsourcing is an effective means of annotating data on a pay-per-task model, leveraging a large pool of global contributors who complete tasks submitted by organizations. This adaptable workforce can quickly scale to meet high annotation demands, making it a cost-effective solution for organizations. Although the scalability and flexibility of crowdsourcing present various challenges, they can be addressed through both technological and human means.1 Crowdsourcing outsources data annotation tasks and deploys the data in a public forum. One of the major challenges associated with crowdsourcing is security. Data is classified into various levels based on its criticality. Publicly available data is harmless and of the lowest criticality, while customer-critical data is of the highest criticality and, if compromised, can cause a significant loss of trust, finances, and reputational status. It is imperative to ensure the safety of such critical data and at the same time provide a method of innovation at scale. In order to protect critical data, understanding its criticality is important. This enables the development of an architecture that can identify, detect, and ensure the safety and security of critical data.
Crowdsourcing Challenges
Crowdsourcing offers a cost-effective way to scale demand, but it also presents several complex issues, including ensuring high-quality work output from crowdsourced workers, managing and monitoring their productivity, addressing potential biases in the collected data, and maintaining high security standards. While technology can provide some support in these areas, such as automated review and feedback mechanisms, human oversight and effort will still be necessary to ensure successful crowdsourcing initiatives. Some of the challenges of crowdsourcing include:
- Quality control—Data quality is a very important aspect of AI models. The higher the data quality, the better the performance. Crowdsourcing works on a pay-per-task model with very little control over the annotation process. With a diverse range of annotators, upholding high data quality becomes challenging due to varying expertise levels. This is further complicated when certain specialized technical skills are required for annotation.2
- Security—Annotated data may contain sensitive or confidential information, making it crucial to ensure its security and privacy. The data on which a model is trained may contain sensitive or confidential information. To avoid a security incident, data must be handled properly when tasks are outsourced to a large pool of workers. To ensure safety, understanding the criticality of data is also important. There are various ways to determine the criticality of data (e.g., rules to detect email addresses, social security numbers, phone numbers, etc.; a machine learning [ML] model to detect composite data). When looked at individually, these types of data may not be critical, but when combined in a certain context they may become highly sensitive.
- Inaccurate and inconsistent annotations—The annotators on a crowdsourcing platform may not be subject matter experts on particular tasks. Also, they may not follow instructions to annotate the data properly for various reasons, such as lack of obligation, excessive cost, etc. Inaccuracies can have severe impacts on the quality and reliability of data.
- Biases—Certain conscious or unconscious biases on the part of annotators can cause issues with annotated data. Ultimately, it depends on the way annotators interpret the data. When bias influences interpretation, the result could be a severe data quality issue. This can be problematic for tasks such as sentiment analysis or image classification.3
- Crowd pool management—With a large annotator pool size, there will be a mix of skills, experience, and motivation. This could lead to management issues for different task types. As the volume of tasks grows, the complexity of cohort management will increase. It is very important to maintain a cohort of skilled annotators to ensure the quality of annotated task delivery.
- Time—Crowdsourcing operates independent of any contractual agreements or service level commitments, which can sometimes result in delays between demand and fulfillment for time-sensitive tasks. However, many crowdsourcing platforms offer features such as expiration times and deadlines to help manage task completion within a specific timeframe. While these tools can help ensure that tasks are completed on time, they may not always guarantee high-quality annotations.
- Language diversity—Most natural language processing (NLP) research projects focus on only 20 of the 7,000 languages in the world. African and Asian languages are among the low-resource languages still understudied.4 Potential reasons include the lack of online infrastructures such as payment methods, Internet connection problems, a shortage of online native talent, and a lack of awareness of online jobs.5
- Motivation—Maintaining worker motivation and engagement can be challenging for repetitive tasks over an extended period. This can lead to lower-quality work and decreased productivity.
- Worker (non-)naivety—Workers may complete the same task several times or share information about tasks with each other. Prior knowledge about the contents or objectives of a task may benefit some crowdsourcing tasks. However, it is possible for workers to have too much information. At the most basic level, if a requester is interested in measuring the average rating of a target to smooth out the idiosyncratic beliefs of workers, it is obviously preferable for several different individuals to rate it than for the same individual to rate it several times.6
By understanding these challenges and implementing strategies to mitigate them, platform providers (customers) can provide a reliable and efficient means of outsourcing annotation tasks to a large pool of workers.
Crowdsourcing Opportunities
Crowdsourcing provides a large pool of annotators with a variety of backgrounds and skillsets. Customers can leverage crowdsourcing platforms such as MTurk or Toloka for data annotation purposes. These platforms are cost-effective and extremely scalable, suited to handling vast quantities of data. Data annotation using crowdsourcing provides numerous opportunities, including:
- Elasticity
- Automation
- Cost savings
In addition to these opportunities, annotation using crowdsourcing platforms can ensure quality, security, consistency, and effective pool management. To achieve these aims, multiple systems can be implemented together (figure 1) to create a cohort (pool of annotators) with specific skillsets, manage the cohort effectively, secure critical data, and ensure high-quality annotations.
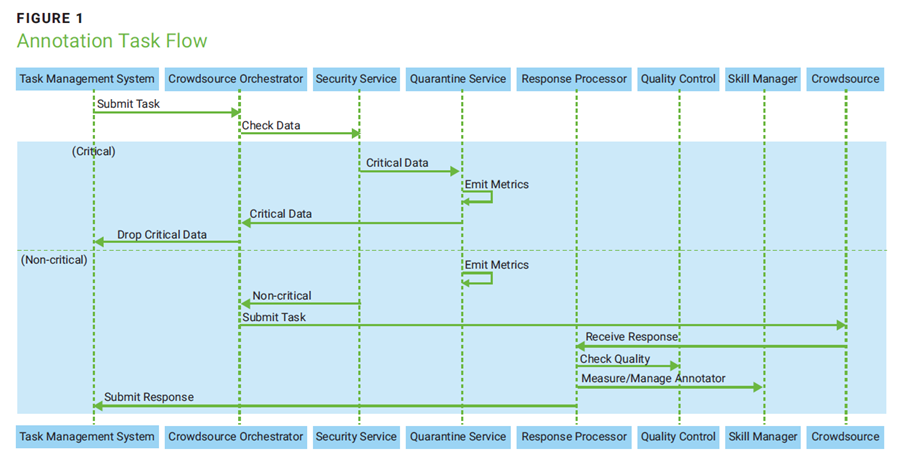
To meet the demand for annotation tasks, an automation suite can be designed and developed to streamline processes (figure 1). Before sharing the task with crowdsourced annotators, a cohort can be established using high-quality ground truth data as a basis. This is done by selecting a group of highly capable annotators based on their performance in a preliminary test task, thereby ensuring that the resulting annotations are of exceptional quality. Creation of this cohort can significantly improve the overall quality of the annotated output. To establish the cohort:
- Create input test tasks with ground truth data.
- Assign these tasks to annotators.
- Evaluate the test output against ground truth data.
- Based on the test output, assign skills to annotators.
- Repeat the process until the required cohort size is reached.
- Ensure that a single annotator is not assigned the same test task twice.
The system can constantly monitor the quality of the annotator based on the output task. Annotated data quality will dictate if an annotator will be the right fit for a given cohort. Various mechanisms to control cohorts can be applied to ensure that annotators in a given cohort meet a specific threshold.
Elasticity
Crowdsourcing platforms have a diverse workforce that can easily scale up and down based on demand. Platforms typically work on a push-and-pull model, with tasks pushed to annotators and annotators pulling them for annotation. Because the annotators are from diverse backgrounds and possess different skillsets, elasticity is necessary to ensure quality control. Each task will require a certain type of expertise, and annotators who possess that expertise can perform the task better. Elasticity can be achieved by matching the skills of a certain set of annotators based on test tasks and ground truth data. The annotators can be asked to perform test assignments and, based on the test responses, multiple skills can be attributed to them. Tasks can then be directed to annotators based on their skills.
Automation
Automation is another important way to meet demand using crowdsourcing. It can be integrated with platforms to enable elastic scaling of demand. Automation can include routing of tasks, conversion Cost of tasks, quality measurement of output, cohort creation, skill assignment, and more (figure 1).
Through automation, multiple channels can be leveraged to annotate huge data sets. Automation can also be used for quality control and cohort management. Components of an automated task annotation system that uses crowdsourcing may include:
- Task management system—This service is used to receive annotation tasks from customers.
- Orchestrator—This service is responsible for orchestrating the routing of tasks based on parameters such as task type, platform type, etc.
- Security control system—This service is used to access the data, and to identify and filter any critical information from routing to the crowdsourced system. The system is rule-based, ML model-based, and security control mechanism-based, which enables it to identify and signal the downstream systems.
- Crowdsourcing platforms—These are end-user platforms, such as Toloka and MTurk, that allow customers to submit tasks and receive annotated responses. There are various controls available to the customers to configure parameters such as task cost, annotator pool, task details, and so forth.
- Response processor—Once an annotator finishes a task, this system processes the response by applying various controls and mechanisms. The response processor measures the output of submitted tasks and then forwards the processed responses to downstream systems.
- Quality control—his system checks the annotated tasks and routes them back to annotation if the quality is poor. Quality is a very important aspect of task annotation, and this system will dynamically discard/accept the task output based on predefined quality criteria. Various ML algorithms are applied at this layer, based on task type, to evaluate the quality.
- Annotator skill manager—This service is used to access the performance of the annotator. Based on the quality of output annotators deliver, their skills can be attributed/removed. In this way, a cohort of highly skilled annotators can be maintained, which ensures the quality of annotated tasks.
Cost
Crowdsourcing allows customers to determine the cost of a given task. Research indicates that monetary reward, skill enhancement, work autonomy, enjoyment, and trust positively influence annotators,7 but these incentives alone will not guarantee the quality of annotated data. Malicious annotators, seeking lucrative rewards, can sign up for tasks and produce poor-quality annotations. Flexibility with cost should be used along with other metrics to ensure that performing tasks is neither highly lucrative nor insufficiently lucrative. Some crowdsourcing platforms provide dynamic pricing features that allow compensation for tasks to be based on the annotator’s skill level. These platforms also provide various reward options—for example, bonuses—to incentivize workers to produce high-quality work.
Quality Control
Quality is a very important aspect of data annotation. There are various ways to control and improve quality, including:
- Skill attribution—A test annotation task can be sent to annotators and, based on output measured against ground truth data, skills can be attributed. Annotation tasks can then be assigned to annotators with the required skillsets.
- Supervisor review—A set of reviewers can manually evaluate the quality.
- Multiple passes—The same task can be assigned to several annotators and consistency can be assessed based on their responses.
- Time to complete—Based on past annotation tasks or knowledge gained from tests, a minimum time to complete a task can be set for future task assignments. This time can be compared against the annotator’s actual time to complete it to determine the likely time it takes for a task to be completed.8
- Identifying poor—quality annotators—Checks can be implemented to identify poor-quality annotators who frequently disagree with peers9 and exclude them from future task assignments.
Quality control can be automated as an independent service to evaluate and update the quality of output produced by annotators (figure 1). The results can determine the next set of tasks an annotator will get. Research shows that the larger the size of the annotator pool, the faster the quality of annotations will improve and stabilize.10 To maintain a highly skilled pool of annotators, various mechanisms can be employed:
- Tests—Annotators can be encouraged to complete test tasks to qualify for given skills. Task test output will be compared against existing ground truth data and, depending on scores, skills can be attributed to the annotators. This can help increase the skilled pool of workers.
- Dynamic quality control—For each response from an annotator, quality can be assessed and the quality score of the given annotator can be dynamically adjusted (figure 1). This will ensure that only high-quality annotators will have particular skills attributed to them. Skill attributions can be maintained based on the performance of the annotators.
- Repetitive testing—To ensure that annotators have the right skillsets, they can be encouraged to repeat tests at intervals. This will refresh the pool of skilled annotators.
- Incentives—Crowdsourcing platforms provide multiple ways to incentivize annotators. Based on skillsets, number of tasks completed, quality, and other factors, incentives can be offered. This may motivate high-quality annotators.
Security
Crowdsourcing tasks are published to a wide range of annotators and can pose a security risk. It is crucial to ensure that tasks with critical data do not end up on crowdsourcing systems (figure 2). To prevent security incidents, a security control (service) must be in place to analyze and filter tasks before their publication. Tasks with critical data can be dropped or sent back to the requester and taken out of the crowdsourcing task pool. To achieve this, an understanding of the criticality of the data posted in the system is essential. When data is observed independently, it often appears that it does not possess any security risk. However, when placed in various contexts and associated with particular entities, the data may be critical. Safeguarding is a two-step process:
- Identify critical data.
- Secure critical data.

Criticality of any given data is determined when it is viewed holistically and combined with various parameters. There are several methods of identifying critical data. The following methods can be used sequentially to optimize processes and cost savings:
- Regex system—Regular expression (regex) is a powerful tool to identify patterns in data (e.g., social security numbers, phone numbers, email addresses). This tool is cheaper and faster than other methods and will be the first line of detection in a sequence.
- Specific security controls—Various security controls are available for an organization to detect critical data. These controls employ different techniques to identify the data. This method can be the second line of detection in the sequence. If regex fails to identify criticality, the system will process the data to identify the criticality.
- ML models—ML models trained to identify critical data are very useful. However, they can be costly in terms of infrastructure, latency, and resources. This tool should be the third line of detection in the sequence. When the data is passed to an ML model, it will be able to look at the data holistically to categorize it, and appropriate action can be taken.
Once the data is identified, the system will act based on the data classification. This can be achieved using:
- Actions—Various actions can be considered based on the level of criticality of data. Once a task is marked critical, it will be taken out of the pool and sent back to the requester with classification and a reason noted. A rule will be updated to mark any such data to achieve optimization. In the future, these types of tasks will never be submitted to the crowdsourcing channels and will be annotated within organizations.
- Monitoring—A service monitor will apply metrics to tasks, which will help the reviewer understand the incoming task and its criticality. Based on the metrics, a rule can be developed to determine appropriate actions, such as rejecting a task, raising an alarm, etc. The metrics of a security service should be revisited and monitored to ensure that the service is up-to-date with the latest security definitions.
- Extra security filtering—Applied at the customer portal, extra filtering will serve as the first layer of defense to protect the data.
Human-in-the-Loop
It is very important to create new skills and cohorts for different kinds of tasks. Various mechanisms can be used to create such cohorts. Human-in-the-loop (HITL) is one such mechanism. A set of annotators creates ground truth data that is then verified by a set of verifiers. Once ground truth is established, it can be used for cohort creation by attributing skills. During the design stage, a new task can be pilot tested by the requester11 and then by a set of annotators to avoid any mistakes.
Conclusion
Crowdsourcing for data annotation tasks has great potential. While there are challenges associated with this approach, they can be mitigated using technology and human input. By designing an automated system and implementing proper quality control and security control measures, a high volume of demand can be met elastically.
While security is one of the major challenges, potential issues can be resolved by using proper security controls. Before the automated system submits the task to the crowdsourcing channel as requested, it takes the opportunity to understand the type of data being annotated. ML models to detect personal identifiable information (PII), personal health information (PHI), and other critical information are used to filter any tasks containing this critical data. These tasks are then rerouted to the requester to ensure that critical data does not leave the organization, strengthening customer trust and safety.
Additionally, a set of ground truth data is used to create a cohort of highly skilled annotators to ensure the quality of the annotated tasks. These annotators can be motivated by a dynamic reward structure to produce high-quality work. Once the annotated data is reported back to the system, a dynamic quality control mechanism is employed to ensure the high quality of data and, in turn, the trained AI model. This dynamic quality control system ranks the annotators to ensure that highly skilled annotators are employed to annotate the data. Further, HITL is employed to ensure the quality of the annotations.
These applications are provided as multiple microservices that comprise a highly scalable system. This will ensure elasticity and keep infrastructure costs at a minimum. Finally, organizations can employ and plug in various security components/controls for scanning the data.
Disclaimer
This work does not relate to the author's position at Amazon.
Endnotes
1 Chandler, J.; Paolacci, G.; et al.; “Risks and Rewards of Crowdsourcing Marketplaces,” Handbook of Human Computation, 5 February 2014, https://doi.org/10.1007/978-1-4614-8806-4_30
2 Dumitrache, A.; Inel, O.; et al.; “Empirical Methodology for Crowdsourcing Ground Truth,” arXiv, 24 September 2018, https://doi.org/10.48550/arXiv.1809.08888
3 Liu, H.; Thekinen, J.; et al.; “Toward Annotator Group Bias in Crowdsourcing,” Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), May 2022, https://aclanthology.org/2022.acl-long.126
4 Ayele, A.; Belay, T.; et al.; “Challenges of Amharic Hate Speech Data Annotation Using Yandex Toloka Crowdsourcing Platform,” WiNLP, 2022, https://www.winlp.org/wp-content/uploads/2022/11/53_Paper.pdf
5 Ohman, E.; “Challenges in Annotation: Annotator Experiences from a Crowdsourced Emotion Annotation Task,” CEUR Workshop Proceedings, 2020, https://ceur-ws.org/Vol-2612/short15.pdf
6 Op cit Chandler
7 Ye, H.; Kankanhalli, A.; “Solvers’ Participation in Crowdsourcing Platforms: Examining the Impacts ofTrust, and Benefit and Cost Factors,” The Journal of Strategic Information Systems, vol. 26, iss. 2, 2017, https://www.sciencedirect.com/science/article/abs/pii/S0963868717300318
8 Le, J.; Edmonds, A.; et al.; “Ensuring Quality in Crowdsourced Search Relevance Evaluation: The Effects of Training Question Distribution,” Proceedings of the SIGIR 2010 Workshop on Crowdsourcing for Search Evaluation (CSE 2010), 23 July 2010,
9 Op cit Chandler
10 Op cit Dumitrache
11 Op cit Chandler
PRANAV KUMAR CHAUDHARY
Is a senior software engineer at Amazon. His expertise includes microservices, distributed computing, cloud computing, cybersecurity, artificial intelligence (AI), generative AI, and mobile applications. Apart from his IT skills, he is also a mentor, author, senior Institute of Electrical and Electronics Engineers (IEEE) member, and peer reviewer at IEEE. He can be reached at chaudhary.pranav@gmail.com.